Для чего нужны мапперы объектов?
Простой ответ: чтобы копировать данные автоматически из одного объекта в другой. Но тогда вы можете спросить: зачем нужно это копирование? Можно усомниться, что это нужно очень часто. Значит следует дать более развернутый ответ.
В мире энтерпрайз приложений принято бить внутреннюю структуру на слои: слой доступа к базе, бизнес и представление/веб сервиса. В слое доступа к базе как правило обитают объекты мапящиеся на таблицы в базе. Условимся называть их DTO (от Data transfer object). По хорошему, они только переносят данные из таблиц и не содержат бизнес логики. На слое представления/веб сервисов, находятся объекты, доставляющие данные клиенту (браузер / клиенты веб сервисов). Назовем их VO (от View object). VO могут требовать только часть тех данных, которые есть в DTO, или же агрегировать данные из нескольких DTO. Они могут дополнительно заниматься локализацией или преобразованием данных в удобный для представления вид. Так что передавать DTO сразу на представление не совсем правильно. Так же иногда в бизнес слое выделяют бизнес объекты BO (Business object). Они являются обертками над DTO и содержат бизнес логику работы с ними: сохранение, модифицирование, бизнес операции. На фоне этого возникает задача по переносу данных между объектами из разных слоев. Скажем, замапить часть данных из DTO на VO. Или из VO на BO и потом сохранить то что получилось.
Если решать задачу в лоб, то получается примерно такой “тупой” код:
…
employeeVO.setPositionName(employee.getPositionName());
employeeVO.setPerson(new PersonVO());
PersionVO personVO = employeeVO.getPerson();
PersonDTD person = employee.getPerson();
personVO.setFirstName(person.getFirstName());
personVO.setMiddleName(person.getMiddleName());
personVO.setLastName(person.getLastName());
...
Знакомо? :) Если да, то могу вас обрадовать. Для этой проблемы уже придумали решение.
Мапперы объектов
Придуманы конечно-же не мной. Реализаций на java много. Вы можете ознакомится, к примеру тут.
Вкратце, задача маппера — скопировать все свойства одного объекта в другой, а так же проделать все то же рекурсивно для всех чайлдовых объектов, по ходу делая необходимые преобразование типов, если это требуется.
Мапперы из списка выше — все разные, более или менее примитивные. Самый мощный пожалуй dozer, с ним я работал около 2 лет, и некоторые вещи в нем перестали устраивать. А вялый темп дальнейшей разработки дозера побудили написать свой “велосипед” (да, я знакомился с другими мапперами — для наших требовний они еще хуже).
Чем плох dozer
- Бедная поддержка конфигурирования через аннотации (есть только
@Mapping). - Невозможно мапить из нескольких полей в одно (к примеру собрать полное имя из имени, фамилии и отчества).
- Проблемы с маппингом генерик свойств. Если в родительском абстрактном классе есть геттер возвращающий генерик тип T, где
<T extends IEntity>, а в чайлде T определен, то при маппинге чайлда будет учитываться только спецификация типа T. Будто бы он IEntity, а не тот, которым он определен в чайлдовом классе… - Классы свойств хранятся как строки во внутреннем кэше дозера, и чтобы получить класс, используется специальный класс лоадер. Проблемы с этим возникают в osgi окружении, когда dozer находится в одном бандле, а нужный класс бина в другом, не доступным из первого. Проблему мы побороли хоть и стандартным способом — подсунув нужный класс лоадер, но сама реализация: хранить класс в виде строки — выглядит странно. Возможно это для того чтобы не создавать perm gen space мемори ликов. Но все равно не очень понятно.
- Если что-то вдруг не мапится, то разобраться в этом очень сложно. Если вы будете дебажить дозер, то поймете почему. Там какое-то… просто сумасшедшее нагромождение ООП паттернов — все запутанно и не явно. Впрочем, это только на мой вкус.
Какими качествами должен обладать маппер?
- Широкая поддержка конфигурации через аннотации.
- Полная поддержка генериков.
- Чистый, понятный код, который сможет подебажить любой не рискуя сломать мозг.
- По умолчанию, без каких либо дополнительных настроек, должно мапить так, как этого скорее всего будет ожидать разработчик.
- Должна быть возможность тонкой настройки (не хуже чем у дозера).
Почему merger а не mapper?
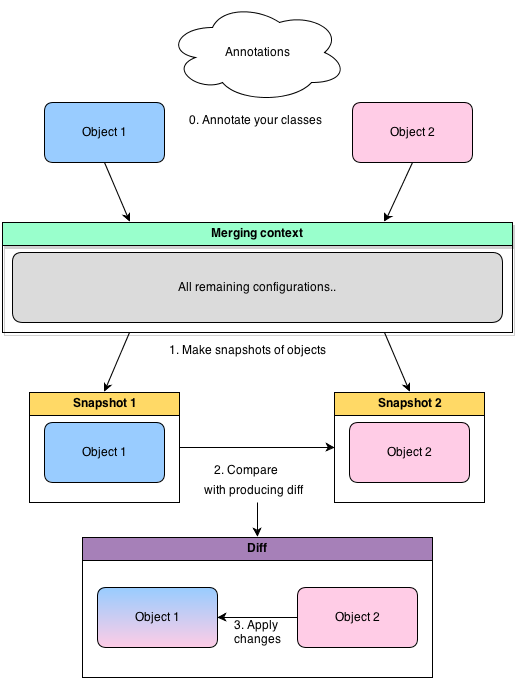
java-object-merger отличает от других мапперов одна особенность. Основополагающая идея была в том, чтобы дать возможность создавать снимки объектов (Snapshot) на некоторый момент времени, и потом, сравнивая их, находить различия (Diff) подобно тому, как находим diff между двумя текстами. Причем должна быть возможность просмотра снапшотов и диффов в понятном для человека текстовом виде. Так, чтобы раз взглянув на дифф сразу стали ясны все отличия, а так же как будет изменен целевой объект после применения диффа. Таким образом добиваемся полной прозрачности процесса. Никакой магии и черных ящиков! Создание снапшотов открывает еще один интересный сценарий. Можно сделать снапшот объекта, потом как-то изменив его, сделать новый снапшот — проверить что изменилось, и, при желании, откатить изменения. Кстати дифф можно обойти специальным visitor-ом, и пометить только те изменения, которые хочется применить, а остальные проигнорировать.
Так что можно сказать, что merger — это нечто большее чем просто mapper.
Использование
Программа “Hello world” выглядит примерно так:
import net.sf.brunneng.jom.IMergingContext;
import net.sf.brunneng.jom.MergingContext;
public class Main {
public static class A1 {
private String field1;
public String getField1() {
return field1;
}
public void setField1(String field1) {
this.field1 = field1;
}
}
public static class A2 {
private String field1;
public A2(String field1) {
this.field1 = field1;
}
public String getField1() {
return field1;
}
}
public static void main(String[] args) {
IMergingContext context = new MergingContext();
A2 a2 = new A2("Hello world!");
A1 a1 = context.map(a2, A1.class);
System.out.println(a1.getField1());
}
}
Во-первых, видим, что для маппинга необходимо, чтобы у свойства был геттер на обоих объектах. Это нужно для сравнения значений. И сеттер у целевого объекта, чтобы записывать новое значение. Сами свойства должны именоваться одинаково.
Посмотрим же как реализован метод map. Это поможет понять многие вещи о библиотеке.
@Override
public <T> T map(Object source, Class<T> destinationClass) {
Snapshot sourceSnapshot = createSnapshot(source);
Snapshot destSnapshot = null;
if (sourceSnapshot.getRoot().getType().equals(DataNodeType.BEAN)) {
Object identifier = ((BeanDataNode)sourceSnapshot.getRoot()).getIdentifier();
if (identifier != null) {
destSnapshot = createSnapshot(destinationClass, identifier);
}
}
if (destSnapshot == null) {
destSnapshot = createSnapshot(destinationClass);
}
Diff diff = destSnapshot.findDiffFrom(sourceSnapshot);
diff.apply();
return (T)destSnapshot.getRoot().getObject();
}
Если исходный снапшот это бин, и если у него есть identifier, тогда пытаемся найти целевой бин для класса destinationClass используя IBeanFinder-ы [тут createSnapshot(destinationClass, identifier);]. Мы такие не регистрировали, да и identifier-а нет, значит идем дальше. В противном случает бин создается используя подходящий IObjectCreator [тут createSnapshot(destinationClass)]. Мы таких тоже не регистрировали, однако в стандартной поставке имеется создатель объектов конструктором по умолчанию — он и используется. Далее у целевого снапшота берется дифф от снапшота источника и применяется к целевому объекту. Все.
Кстати, дифф, для этого простого случая, будет выглядеть так:
MODIFY {
dest object : Main$A1@28a38b58
src object : Main$A2@76f8d6a6
ADD {
dest property : String field1 = null
src property : String field1 = "Hello world!"
}
}
Основные аннотации
Находятся в пакете
net.sf.brunneng.jom.annotations.@Mapping— задает путь к полю для маппинга на другом конце ассоциации (например“employee.person.firstName”). Может быть указано на классе целевого объекта или объекта источника.@Skip— поле не попадает в снапшот, не сравнивается и не мапится.@Identifier— помечает поле которое считаеся идентификатором бина. Таким образом при сравнении коллекций мы будем знать какой объект с каким должен сравниваться. А именно будут сравниваться объекты с совпадающими идентификаторами. Так же, если в процессе применения диффа возникнет потребность создать бин, и при этом известен идентификатор, то будет попытка вначале найти этот бин при помощи зарегистрированныхIBeanFinder-ов. Так, реализацияIBeanFInderможет искать бины к примеру в базе данных.@MapFromMany— то же самое что и @Mapping только указывается на классе целевого объекта и позволяет указать массив свойств на объекте источнике которые будут мапится на поле в целевом объекте.@Converter— позволяет задать на свойстве класс наследникPropertyConverter. — он выполнит преобразование между свойствами. Конвертер свойств обязателен при маппинге нескольких полей на одно, т.к. он как раз и должен будет собрать все значения из источника воедино и сформировать из них одно значение.@OnPropertyChange, @OnBeanMappingStarted, @OnBeanMappingFinished— позволяют пометить методы прослушивающие соответствующие эвенты в жизненном цикле маппинга, которые происходят в данном бине.- И другие.
Преобразования типов
В IMergingContext можно регистрировать пользовательские преобразователи типов, из одного типа в другой (интерфейс
TypeConverter). Стандартный набор преобразователей включает преобразования:- примитивных типов в обертки, и наоборот
- преобразования дат
- объектов в строку
- энумы в энумы, и строки в энумы по имени константы энума
Категории объектов
Маппер разделяет все объекты на такие категории как:
- Объекты значения: примитивные типы, объекты в пакете
java.lang, даты, массивы объектов значений. Список классов считающихся значениями можно расширять черезIMergingConext. - Коллекции — массивы, все наследующиеся от
java.util.Collection. - Мапы — все наследующиеся от
java.util.Map. - Бины — все остальные.
Производительность
Честно говоря, пока писал библиотеку — о производительности особо не задумывался. Да и изначально в целях высокой производительности не было. Однако, решил замерять время маппинга N раз на один тестовый объект. Исходный код теста. Объект довольно сложный, с полями значениями, дочерними бинами, коллекциями и мапами. Для сравнения взял dozer последней на текущий момент версии 5.4.0. Ожидал, что дозер не оставит никаких шансов. Но получилось совсем наоборот! dozer замапил 5000 тестовых объектов за 32 секунды, а java-object-merger 50000 объектов за 8 секунд. Разница какая-то дикая — в 40 раз…
Применение
java-object-merger был опробован на текущем проекте с моей основной работы (osgi, spring, hibernate, сотни мапящихся классов). Чтобы заменить им дозер полностью ушло менее 1 дня. По ходу находились некоторые явные косяки, но, после исправления, все основные сценарии работали нормально.
Ленивые снапшоты
Одна из явных проблем, найденных во время прикручивания маппера к реальному проекту было то, что если делать снапшот на DTO у которой есть ленивые списки других сущностей, а те другие ссылаются на третьи и т.д, то за создание одного снапшота можно, ненароком, выкачать пол базы. Поэтому было решено сделать все свойства в снапшоте ленивыми по умолчанию. Это означает, что они не будут вытаскиваться из объектов до момента сравнения с соответствующим свойством при взятии диффа. Или пока явно не вызовем на снапшоте метод
loadLazyProperties(). А при вытаскивании свойства происходит автоматическое достраивание снапшота — опять же с ленивыми свойствами, которые ждут пока их догрузят.Заключение
Если заинтересовал — проект, с исходниками и документацией находится тут . Вся основная функциональность библиотеки покрыта юнит тестами, так что можете не сомневаться в том, что каких-то глупых тривиальных ошибок вы в ней не увидите. Практически все классы и методы задокументированы javadoc-ом.
Качайте, пробуйте, пишите свои отзывы :). Обещаю оперативно реагировать и прислушиваться к вашим пожеланиям.
This entry passed through the Full-Text RSS service — if this is your content and you're reading it on someone else's site, please read the FAQ at fivefilters.org/content-only/faq.php#publishers. Five Filters recommends:
- Massacres That Matter - Part 1 - 'Responsibility To Protect' In Egypt, Libya And Syria
- Massacres That Matter - Part 2 - The Media Response On Egypt, Libya And Syria
- National demonstration: No attack on Syria - Saturday 31 August, 12 noon, Temple Place, London, UK
Комментариев нет:
Отправить комментарий