Я опять предупреждаю, что все что вы читаете — написано дважды гуманитарием (бакалавром и магистром), поэтому слепо верить не стоит. Вообщем, вы предупреждены.
Замечания про ошибки (математические) приветствуются.
Еще одно предупреждение — очень много картинок.
Картинка для привлечения внимания (никак не относящаяся к нашему тексту).

Как вы думете, не разрывая эти фигуры, но деформируя любым образом, можно ли их рассоединить?
Первоначально я планировал во второй части рассказать о метрических пространствах, но потом решил отложить это на будщее, а сейчас поговорить более подробно об окрестностях и связаных с ними понятиях, о которых в прошлой части лишь кратко упомянул. Таким образом мы находимся где-то в первой главе какой-нибудь книги по «Общей топологии».
Черный сплошной контур на рисунках будет обозначать замкнутые множества, а множества без контура будут открытыми. Буквами ттт я буду сокращать тогда и только тогда.
Поехали.
Итак, подмножество U топологического пространства (X, T) называется окрестностью точки х ттт, когда в U лежит открытое множество содержащее х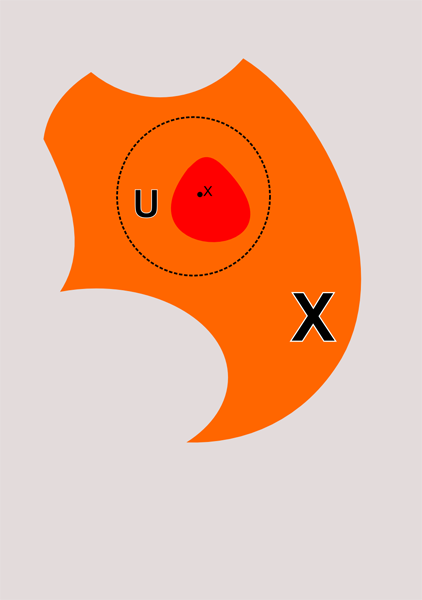
На рисунке сверху эта ситуация проиллюстрирована. Я показал окрестность точки x в виде круга ограниченого пунктинрной линией. Конечно, окресность не обязана быть кругом. Она лишь должна содержать в себе открытое множество, которому принадлежит точка x. В данном случае это множеств я изобразил красным цветом. Поскольку всякое множество принадлежит самому себе, то очевидно, что всякое открытое множество является окрестностью каждой своей точки. Обратное не верно. Окрестность совсем не обязана быть открытым множеством. На рисунке снизу я проиллюстрировал эти ситуации.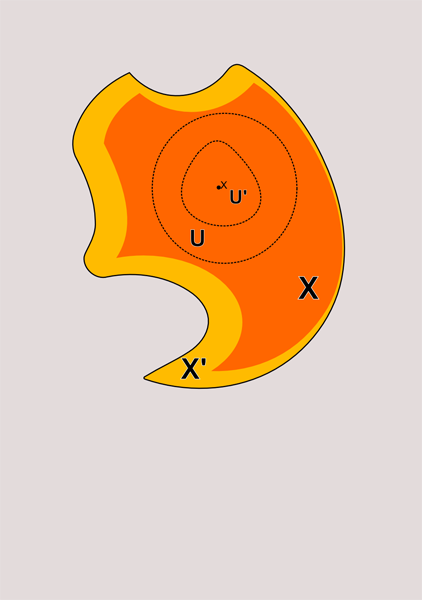
U, U' и Х и X' являются окрестностями x. При этом U, U' и Х открыты, а X' нет.
Из всего этого следует очень важная теорема (а может и не очень) — множество открыто ттт, когда оно содержит окрестности всех своих точек.
Я долго думал, как это нарисовать. Получился вот такой рисунок как внизу.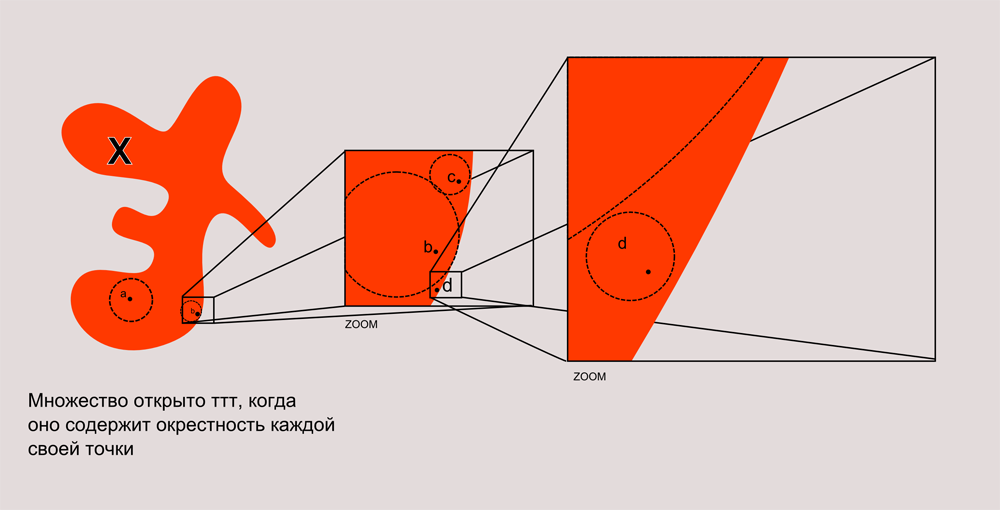
Посмотрите на это множество X. Если это множество открыто то, какую бы точку вы не нашли в нем у нее всегда будет окресность принадлежащее данному множеству. Я показал, как это будет выглядеть при увеличении картинки. Например, точка d лежит почти на самом краю, но если присмотрется к этому участку внимательнее, то видно, что вокруг нее всегда можно описать открытый круг. Можно представить себе такую игру. Пусть демон и гений выбирают случайное множество. Демон ставит на то, что множество не открыто, а гений, что открыто. После этого, демон указывает какую-нибудь точку множества, а гений, пробует нарисовать вокруг нее окрестность. Если все удается, то получает приз, а демон загадывает новую точку. Если гению повезет с множеством, может выйграть целую бесконечность призов. Конечно, смертным созданиям в такую игру не слишком акутально играть.
Существует важный тип точек, которые называются точками накопления или предельными точками.
Предельная точка—это точка, подмножества А топологического пространства (X,T), в любой окрестности которой находится точка подмножества А.
Уф. Если говорить опираясь на визуальную интуици, то предельные точки это те точки, которые лежат «внутри» множества или на «краю». Не любая точка, которая принадлежат множеству, является предельной. Посмотрите на картинку ниже.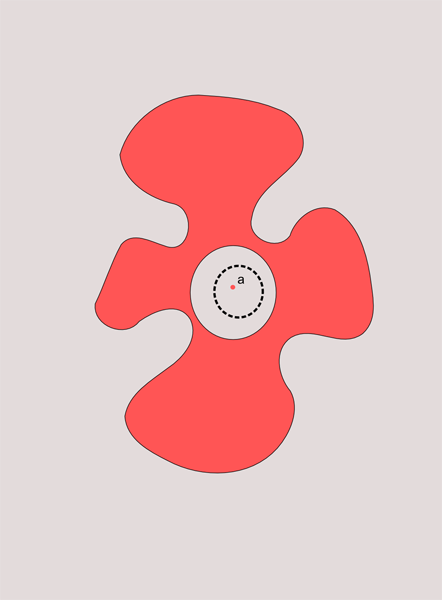
Точка а принадлежит красноватому множеству, но у нее есть окрестность в которой нету других точек этого множества. Значит она не предельная. И, наоборот, есть такие точки, которые могут этому множеству не принадлежать, но все-таки быть для него предельными.
На картинке ниже показаны разные ситуации.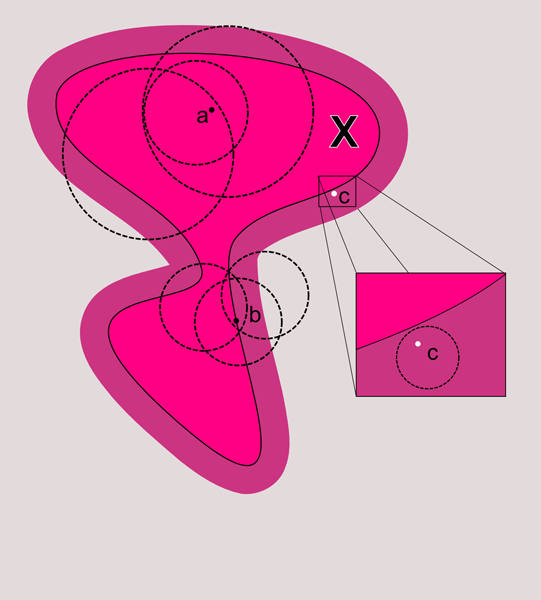
Точка а содержит в любой своей окрестности точку подмножества X. Точка b также. Следовательно, они являютя точками накопления. А вот точка c хотя и имеет окрестности в которых содержатся точки X, но имеет и другие окрестности, которые не содержат точек из X.
Окрестность в данном случе очень похожа на понятие окрестности в бытовом смысле — лежать в окрестности, значит быть по близости. В каком-то смысле окрестность выражает близость. Но важно понимать, что пока все пространства о которых мы говорим не снабжены метрикой, т.е. не имеют расстояния и мы не можем выразить близость численно. Позже, когда мы будем говорить о метрических пространствах, мы вновь вернемся к теме окрестности, но уже с немного другой стороны.
Все сказанное позволяет сфрмулировать определение замкнутых множеств на новом языке. В прошлый главе я говорил, что замкнутые множества — те, которые являются дополнением к открытым. Это довольно офрмальное определение, но окрестности позволяют увидеть его в новом свете и оно неожиданно приобретает глубину и как бы новые грани.
Итак, подмножество топологического пространства замкнуто тогда, когда оно содержит все свои предельные точки.
Посмотрите на рисунок.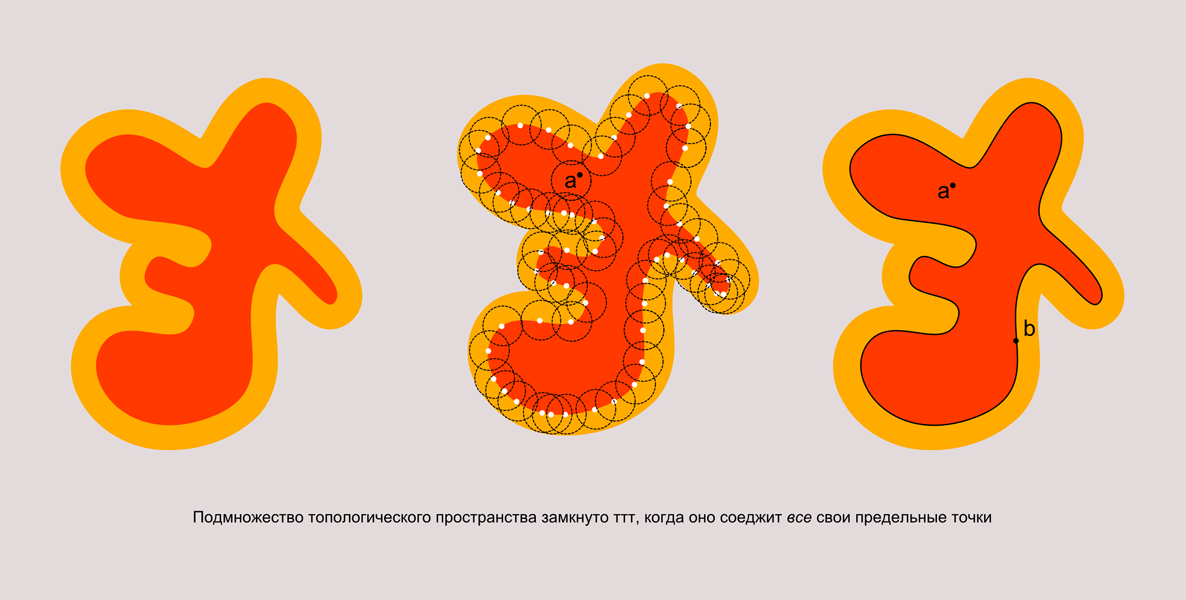
У нас есть красное множество, которое является подмножестовм оранжевого множества. Оно открыто, так как все его точки входят в него со своей окрестностью. И, очевидно, существует бесконечное число предельных точек, которые ему не принадлежат. Я нарисовал несколько из них на рисунке посередине. Если мы добавим к множеству множество всех его предельных точек, то оно станет замкнутым.
Как это доказывается? Ну, здесь все просто. Допустим А подмножество топологического пространства X. Есть точка x, которая не принадлежит А и имеет открытую окрестность U, которая не пересекает А. так как эта окрестность открыта, то она является окрестностью любой своей точки. Раз она не пересекает А, значит ни одна точка этой окрестности не является предельной точкой множества А. Это значит, что (А∪множество его предельных точек)∪ открытое U= X. Или X\(А∪множество его предельных точек)= открытое множество
Т.е. А вместе с множеством своих предельных точек, является дополнением к открытому множеству, а значит замкнуто. Удивительно, как понятие окрестности оказалось глубоко связано с понятием открытости и замкнутости.
Теперь определим тесно связанное с замкнотостью понятие замыкание
Замыкание подмножества X — пересечение всех замкнутых множеств, которые содержат X. Замыкание X обозначается, например, так [X]. Замыкание подмножества — замкнутое множество, потому что пересечение замкнутых множеств замкнуто. И очевидно, что замыкание—самое маленькое замкнутое множество, которое содержиит X
Вот посмотрите на картинку.
У нас есть замкнутое желтое множество и оранжевое открытое. Если мы последовательно пересечем все замкнутые множества, которрые содержат оранжевое (я показал только некоторые шаги), то получим замыкание оранжевого множества.
Думаю, вы догадались, множество является замкнутым ттт, когда оно совпадает со своим замыканием ([X]=X).
Замкнутое множество — это множество, которое содержит все свои предельные точки, верно и то, что замыкание—это объединение множества и его предельных точек. Это кажется тривиальным, но этот факт нужно доказать. Доказывается просто — предельные точки множества X являются, что очевидно, и предельными точками каждого множества содержащего X. Значит они принадлежит и каждому замкнутому множеству содержащему X. Следовательно, предельные точки X содержатся и в любом пересечении этих множеств, т.е. в [X]. С другой стороны множество вместе со своими предельными точками замкнуто, а значит замыкание множества Х это множество Х вместе его предельными точками.
Оператор, который ставит некоторому множеству в соответсвие его замыкание называют оператором замыкания. Я буду его обозначать так ⊛. Обычно в математике его так не обозначают, но мы ведь имеем право на свои обозначения.
У него есть несколько свойств:
1)⊛∅=∅
Это значит, что замыкание пустого множества пусто.
2)X⊆⊛X
Множество содержится в своем замыкании.
3)⊛X=⊛⊛X
Замыкание замыкания множества равно замыканию множества
4)⊛X∪⊛X'=⊛(X∪X')
Объединение замыканий равно замыканию объединения.
Эти правила называются аксиомами замыкания Куратовского.
Мне кажется один из лучших способов понять топологию, это рассмотреть какое-нибудь очень маленькое топологическое пространство. Например, такое которое состоит всего из нескольких элементов.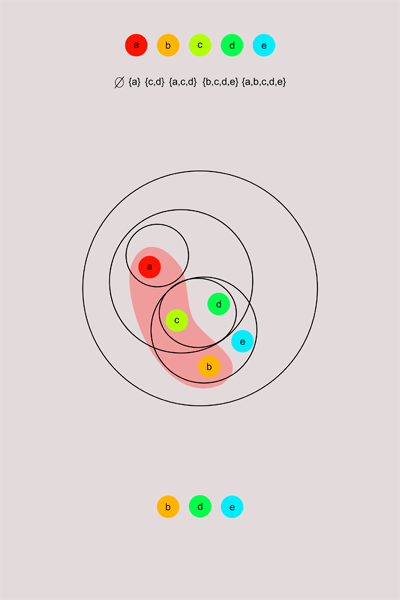
Допустим, у нас есть множество {a,b,c,d,e} снабженное топологией описанной на рисунке. Рассмотрим подмножество этого множества {a,b,c}. Какие точки являются предельными для него в данной топологии? По определению, это будут те точки, которые имеют в каждой своей окрестности точки из {a,b,c} помимо самих себя. Я показал открытые окрестности схематически с помощью окружностей. Точки внутри одного круга—находятся в одной окрестности (или в одном открытом подмножестве множества). Поэтому проверим для каждой точки нет ли у нее окрестности, в которой нет точек из {a,b,c}. У точки a, такая окрестность есть. Это окрестность, где содержится лишь точка а. Значит она не предельная точка. Во всех окрестностях b есть точки из {a,b,c} (помимо самой b). Аналогично для d и e. И т.д. таким образом из данной схемы мы видим, что b,d,e являются предельными точками для {a,b,c}, но а и с нет.
Снабдим это же пространств антидискретной топологией и посмотрим что будет.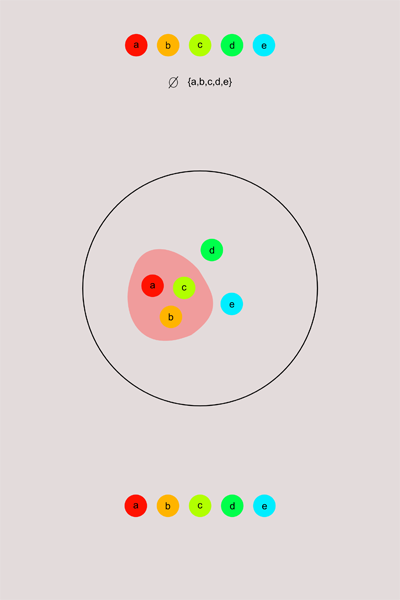
В антидискретной топологии каждая точка будет предельной для множества {a,b,c} (и для любого другого, кроме самого множества и пустого множества). Эту топологию не зря называют топологией слипшихся точек, в ней все точки пространства как бы слиплись друг с другом, прямо и не разберешь где что. Не хотел бы жить во вселенной с антидискретной топологией.
В дискретной топологии мы имеем противоположную ситуацию. Я пытался нарисовать, но честно говоря, отказался от данной идеи. Вы ведь помните как много открытых множеств там получится даже в сравнительно небольшом множестве.
Глядя на все эти картинки, хочется определить понятие внутренности множества и границы. Например, когда я рисовал множества очерченые черным контуром, то сразу хотелось назвать эту линию границей множества. Однако до сих пор у нас не было понятие границы и внутренности. А сейчас будет.
Точка называется внутренней точкой множества, когда множество является его окрестностью. Внутренность множества — это совокупность всех его внутренних точек. По другому говоря внутренность множества — наибольшее открытое множество содержащееся в нем. Т.е. множество открыто лишь когда оно совпадает со своей внутренностью. Согласитесь, это очень похоже на определение замыкания.
Внутренность любого подмножества антидискретного пространства пуста. В дискретном простанстве любое подмножество совпадает со своей внутренностью и со своим замыканием одновременно.
Граница множества X (X подмножество A) — это множество тех точек множества A, окрестность которых содержит как точки X, так и A/X.
Я нарисовал такую картинку, немного в стиле абстракционистов вышло.
Ну вот. на этой ноте я заканчиваю статью. Для упражнения вы можете подумать над тем, какие точки являются границей множества {a,b,c} с картинки, какие ее внутренностью (если есть), какое у него замыкание. Ну и, конечно, можно ли расцепить фигуры из начальной картинки. И как это сделать (очень развивает пространственное мышление). Ответ на последний вопрос обещаю приложить к следующим статьям.
Пока все.
This entry passed through the Full-Text RSS service — if this is your content and you're reading it on someone else's site, please read the FAQ at fivefilters.org/content-only/faq.php#publishers. Five Filters recommends:
- Massacres That Matter - Part 1 - 'Responsibility To Protect' In Egypt, Libya And Syria
- Massacres That Matter - Part 2 - The Media Response On Egypt, Libya And Syria
- National demonstration: No attack on Syria - Saturday 31 August, 12 noon, Temple Place, London, UK
 Веб-разработка
Веб-разработка CSS
CSS JavaScripts
JavaScripts Браузеры
Браузеры Новости
Новости
 Демо
Демо Сайты с интересным дизайном и функциональностью
Сайты с интересным дизайном и функциональностью
 Занимательное
Занимательное

























{kind=link}