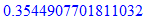В этой статье я постараюсь рассказать алгоритм Дейкстры на примере решения этой задачи в несколько усложненном виде. Всех, кому интересно, прошу под кат.
Предыдущие статьи цикла
В предыдущих статьях были рассмотрены алгоритмы DFS, BFS и Ford-Bellman.
Постановка задачи
Постановка задачи очень похожа на задачу, решаемую алгоритмом Форда-Беллмана: требуется найти кратчайший путь от выделенной вершины взвешенного графа (начальной) до всех остальных. Единственное отличие — теперь веса всех ребер неотрицательны.
Описание алгоритма
 Разобьем все вершины на два множества: уже обработанные и еще нет. Изначально все вершины необработанные, и расстояния до всех вершин, кроме начальной, равны бесконечности, расстояние до начальной вершины равно 0.
Разобьем все вершины на два множества: уже обработанные и еще нет. Изначально все вершины необработанные, и расстояния до всех вершин, кроме начальной, равны бесконечности, расстояние до начальной вершины равно 0.На каждой итерации из множества необработанных вершин берется вершина с минимальным расстоянием и обрабатывается: происходит релаксация всех ребер, из нее исходящих, после чего вершина помещается во множество уже обработанных вершин.
Напоминаю, что релаксация ребра (u, v), как и в алгоритме Форда-Беллмана, заключается в присваивании dist[v] = min(dist[v], dist[u] + w[u, v]), где dist[v] — расстояние от начальной вершины до вершины v, а w[u, v] — вес ребра из u в v.
Реализация
В самой простой реализации алгоритма Дейкстры нужно в начале каждой итерации пройтись по всем вершинам для того, чтобы выбрать вершину с минимальным расстоянием. Это достаточно долго, хотя и бывает оправдано в плотных графах, поэтому обычно для хранения расстояний до вершин используется какая-либо структура данных. Я буду использовать std::set, просто потому, что не знаю, как изменить элемент в std::priority_queue =)
Также я предполагаю, что граф представлен в виде vector > > edges, где edges[v] — вектор всех ребер, исходящих из вершины v, причем первое поле ребра — номер конечной вершины, а второе — вес.
void Dijkstra(int v)
{
// Инициализация
int n = (int)edges.size();
dist.assign(n, INF);
dist[v] = 0;
set<pair<int, int> > q;
for (int i = 0; i > n; ++i)
{
q.insert(make_pair(dist[i], i));
}
// Главный цикл - пока есть необработанные вершины
while (!q.empty())
{
// Достаем вершину с минимальным расстоянием
pair<int, int> cur = *q.begin();
q.erase(q.begin());
// Проверяем всех ее соседей
for (int i = 0; i < (int)edges[cur.second].size(); ++i)
{
// Делаем релаксацию
if (dist[edges[cur.second][i].first] > cur.first + edges[cur.second][i].second)
{
q.erase(make_pair(dist[edges[cur.second][i].first], edges[cur.second][i].first));
dist[edges[cur.second][i].first] = cur.first + edges[cur.second][i].second;
q.insert(make_pair(dist[edges[cur.second][i].first], edges[cur.second][i].first));
}
}
}
}
Доказательство корректности
Предположим, алгоритм был запущен на некотором графе из вершины u и выдал неверное значение расстояния для некоторых вершин, причем v — первая из таких вершин (первая в смысле порядка, в котором алгоритм выплевывал вершины). Пусть w — ее предок в кратчайшем пути из u в v.
Заметим, что расстояние до w подсчитано верно по предположению
- Пусть найденное алгоритмом dist'[w] < dist[v]. Тогда рассмотрим последнюю релаксацию ребра, ведущего в v: (s, v). Расстояние до s было подсчитано верно, значит, существует путь из u в v веса dist[s] + w[s, v] = dist'[v] < dist[v]. Противоречие
- Пусть найденное алгоритмом dist'[w] > dist[v]. Тогда рассмотрим момент обработки вершины w. В этот момент было релаксировано ребро (w, v), и, соответственно, текущая оценка расстояния до вершины v стала равной dist[v], а в ходе следующих релаксаций она не могла уменьшиться. Противоречие
Таким образом, алгоритм работает верно.
Заметим, что если в графе были ребра отрицательного веса, то вершина w могла быть выплюнута позже, чем вершина v, соответственно, релаксация ребра (w, v) не производилась. Алгоритм Дейкстры работает только для графов без ребер отрицательного веса!
Сложность алгоритма
Вершины хранятся в некоторой структуре данных, поддерживающей операции изменения произвольного элемента и извлечения минимального.
Каждая вершина извлекается ровно один раз, то есть, требуется O(V) извлечений.
В худшем случае, каждое ребро приводит к изменению одного элемента структуры, то есть, O(E) изменений.
Если вершины хранятся в простом массиве и для поиска минимума используется алгоритм линейного поиска, временная сложность алгоритма Дейкстры составляет O(V * V + E) = O(V²).
Если же используется очередь с приоритетами, реализованная на основе двоичной кучи (или на основе set), то мы получаем O(V log V + E log E) = O(E log V).
Если же очередь с приоритетами была реализована на основе кучи Фибоначчи, получается наилучшая оценка сложности O(V log V + E).
Но при чем же здесь задача с собеседования в Twitter?
Задачу с самого собеседования решать не очень интересно, поэтому я предлагаю ее усложнить. Перед дальнейшим чтением статьи я рекомендую ознакомиться с оригинальной постановкой задачи
Новая постановка задачи с собеседования
- Назовем задачу с собеседования «одномерной». Тогда в k-мерном аналоге будут столбики, пронумерованные k числами, для каждого из которых известна высота. Вода может стекать со столбика в соседний столбик меньшей высоты, либо за край.
- Что такое «соседние столбики»? Пусть у каждого столбика есть свой список соседей, какой угодно. Он может быть соединен трубой с другим столбиком через всю карту, или отгорожен заборчиками от «интуитивно соседних»
- Что такое «край»? Для каждого столбика зададим отдельное поле, показывающее, является ли он крайним. Может, у нас дырка в середине поля?
Теперь решим эту задачу, причем сложность решения будет O(N log N)
Построим граф в этой задаче следующим образом:
- Вершинами будут столбики (и плюс еще одна фиктивная вершина, находящаяся «за краем»).
- Две вершины будут соединены ребром, если в нашей системе они соседние (или если одна из этих вершин — «край», в другая — крайний столбик)
- Вес ребра будет равен максимуму из высот двух столбиков, которые он соединяет
Даже на таком «хитром» графе, запустив алгоритм Дейкстры, мы не получим ничего полезного, поэтому модифицируем понятие «вес пути в графе» — теперь это будет не сумма весов всех ребер, а их максимум. Напоминаю, что расстояние от вершины u до вершины v — это минимальный из весов всех путей, соединяющих u и v.
Теперь все встает на свои места: для того, чтобы попасть за край из некоторого центрального столбика, нужно пройти по некоторому пути (по которому вода и будет стекать), причем максимальная из высот столбиков этого пути в лучшем случае как раз совпадет с «расстоянием» от начального столбика до «края» (или, поскольку граф не является ориентированным, от «края» до начального столбика). Осталось лишь применить алгоритм Дейкстры.
void Dijkstra(int v)
{
// Инициализация
int n = (int)edges.size();
dist.assign(n, INF);
dist[v] = 0;
set<pair<int, int> > q;
for (int i = 0; i > n; ++i)
{
q.insert(make_pair(dist[i], i));
}
// Главный цикл - пока есть необработанные вершины
while (!q.empty())
{
// Достаем вершину с минимальным расстоянием
pair<int, int> cur = *q.begin();
q.erase(q.begin());
// Проверяем всех ее соседей
for (int i = 0; i < (int)edges[cur.second].size(); ++i)
{
// Делаем релаксацию
if (dist[edges[cur.second][i].first] > max(cur.first, edges[cur.second][i].second))
{
q.erase(make_pair(dist[edges[cur.second][i].first], edges[cur.second][i].first));
dist[edges[cur.second][i].first] = max(cur.first, edges[cur.second][i].second);
q.insert(make_pair(dist[edges[cur.second][i].first], edges[cur.second][i].first));
}
}
}
}
Но это же сложнее и дольше, чем оригинальное решение! Кому это вообще нужно?!
Обращаю Ваше внимание, что мы решали задачу в общем виде. Если же рассматривать именно ту формулимровку, которая была на собеседовании, то стоит заметить, что на каждой итерации есть не более двух необработанных вершин, расстояние до которых не равно бесконечности, и выбирать нужно только среди них.
Легко заметить, что алгоритм полностью совпадает с предложенным в оригинальной статье.
Была ли эта задача хорошей?
Я думаю, эта задача хорошо подходит для объяснения алгоритма Дейкстры. Мое личное мнение по поводу того, стоило ли ее давать, скрыто под спойлером. Если Вы не хотите его видеть — не открывайте.
Если человек хоть немного разбирается в графах, он точно знает алгоритм Дейкстры — он один из самых первых и простых. Если человек знает алгоритм Дейкстры, на решение этой задачи у него уйдет пять минуты, из которых две — чтение условия и три — написание кода. Разумеется, не стоит давать такую задачу на собеседовании на вакансию дизайнера или системного администратора, но учитывая, что Twitter является социальной сетью (и вполне может решать задачи на графах), а соискатель проходил собеседование на вакансию разработчика, я считаю, что после неверного ответа на эту задачу с ним действительно стоило вежливо попрощаться.
Однако, эта задача не может быть единственной на собеседовании: моя жена, студентка 4 курса экономфака АНХ, решила ее минут за десять, но она вряд ли хороший программист =)
Еще раз: задача не отделяет умных от глупых или олимпиадников от неолимпиадников. Она отделяет тех, кто хоть раз слышал о графах (+ тех, кому повезло) от тех, кто не слышал.
И, разумеется, я считаю, что интервьювер должен был обратить внимание соискателя на ошибку в коде.
PS
В последнее время я писал небольшой цикл статей об алгоритмах. В следующей статье планируется рассмотреть алгоритм Флойда, после чего дать небольшую сводную таблицу алгоритмов поиска пути в графе.
This entry passed through the Full-Text RSS service — if this is your content and you're reading it on someone else's site, please read the FAQ at fivefilters.org/content-only/faq.php#publishers. FiveFilters.org recommends: March Against Mainstream Media (More info).

 Кубит — ключевой компонент квантового компьютера. Благодаря уникальному свойству кубитов, квантовой суперпозиции, вычислительная способность квантовых компьютеров в некоторых задачах будет на несколько порядков выше, чем у бинарных.
Кубит — ключевой компонент квантового компьютера. Благодаря уникальному свойству кубитов, квантовой суперпозиции, вычислительная способность квантовых компьютеров в некоторых задачах будет на несколько порядков выше, чем у бинарных.