суббота, 29 ноября 2014 г.
Тонкости nodejs. Часть II: Работа c ошибками
Корень зла
Реализация объекта ошибки в JS – одна из самых ужасных, которые я когда либо встречал. Мало того сама реализация отличается в различных движках. Объект спроектирован (и развивается) так будто ни до, ни после возникновения JS с ошибками вообще не работали. Я даже не знаю с чего начать. Этот объект не является программно-интерпретируемым, так как все важные значения являются склеенными строками. Отсутствует механизм захвата стека вызовов и алгоритм расширения ошибки.
Результатом этого является то, что каждый разработчик вынужден самостоятельно принимать решение в каждом отдельном случае, но, как доказали ученые, выбор вызывает у людей дискомфорт, поэтому очень часто ошибки просто-напросто игнорируются и попадают в основной поток. Так же, достаточно часто, вместо ошибки вы можете получить Array или Object, спроектированные "на свое усмотрение". Поэтому вместо единой системы обработки ошибок мы сталкиваемся с набором уникальных правил для каждого отдельного случая.
И это не только мои слова, тот же TJ Holowaychuck написал об этом в своем письме прощаясь с сообществом nodejs.
Как же решить проблему? Создать единую стратегию формирования и обработки сообщения об ошибке! Разработчики Google предлагают пользователям V8 собственный набор инструментов, которые облегчают эту задачу. И так приступим.
MyError
Давайте начнем с создания собственного объекта ошибки. В классической теории, все что вы можете сделать – создать экземпляр Error, а затем дополнить его, вот как это выглядит:
var error = new Error('Some error');
error.name = 'My Error';
error.customProperty = 'some value';
throw error;
И так для каждого случая? Да! Конечно, можно было бы создать конструктор MyError и в нем установить нужные значения полей:
function MyError(message, customProperty) {
Error.call(this);
this.message = message;
this.customProperty = customProperty;
}
Но так мы получим в стеке лишнюю запись об ошибке, что усложнит поиск ошибки другим разработчикам. Решением является метод Error.captureStackTrace. Он получает на вход два значения: объект, в который будет записан стек и функция-конструктор, запись о которой из стека нужно изъять.
function MyError(message, customProperty) {
Error.captureStackTrace(this, this.constructor);
this.message = message;
this.customProperty = customProperty;
}
// Для успешного сравнения с помощью ...instanceof Error:
var inherits = require('util').inherits;
inherits(MyError, Error);
Теперь где бы не всплыла ошибка в стеке на первом месте будет стоять адрес вызова new Error.
message, name и code
Следующим пунктом в решении проблемы стоит идентификация ошибки. Для того чтобы программно ее обработать и принять решение о дальнейших действиях: выдать пользователю сообщение или завершить работу. Поле message не дает таких возможностей: парсить сообщение регулярным выражением не представляется разумным. Как же тогда отличить ошибку неверного параметра от ошибки соединения? В самом nodejs для этого используется поле code. При этом в стандарте для классификации ошибок предписывается использовать поле name. Но используются они по разному, поэтому рекомендую использовать для этого следующие правила:
- Поле name должно содержать значение в "скачущем" регистре:
MyError. - Поле code должно содержать значение разделенное подчеркиванием, символы должны быть в верхнем регистре:
SOMETHING_WRONG. - Не используйте в поле code слово
ERROR. - Значение в name создано для калссификации ошибок, поэтому лучше использовать
ConnectionErrorлибоMongoError, вместоMongoConnectionError. - Значение code должно быть уникальным.
- Поле message должно формироваться на основе значения code и переданных переменных параметров.
- Для успешной обработки ошибки желательно добавить дополнительные сведения в сам объект.
- Дополнительные значения должны быть примитивами: не стоит передавать в объект ошибки соединение с базой данных.
Пример:
Чтобы создать отчет об ошибке чтения файла по причине того что файл отсутствует можно указать следующие значения: FileSystemError для name и FILE_NOT_FOUND для code, а также к ошибке следует добавить поле file.
Обработка стека
Так же в V8 есть функция
Error.prepareStackTrace для получения сырого стека – массива CallSite объектов. CallSite – это объекты, которые содержат информацию о вызове: адрес ошибки (метод, файл, строка) и ссылки непосредственно на сами объекты чьи методы были вызваны. Таким образом в наших руках оказывается достаточно мощный и гибкий инструмент для дебага приложений.Для того чтобы получить стек необходимо создать функцию, которая на вход получает два аргумента: непосредственно ошибка и массив CallSite объектов, вернуть необходимо готовую строку. Эта функция будет вызываться для каждой ошибок, при обращении к полю stack. Созданную функцию необходимо добавить в сам Error как prepareStackTrace:
Error.prepareStackTrace = function(error, stack) {
// ...
return error + ':\n' + stackAsString;
};
Давайте подробнее рассмотрим объект CallSite содержащийся в массиве stack. Он имеет следующие методы:
| getThis | возвращает значение this. |
| getTypeName | возвращает тип this в виде строки, обычно это поле name конструктора. |
| getFunction | возвращает функцию. |
| getFunctionName | возвращает имя функции, обычно это значение поля name. |
| getMethodName | возвращает имя поля объекта this. |
| getFileName | возвращает имя файла (или скрипта для браузера). |
| getLineNumber | возвращает номер строки. |
| getColumnNumber | возвращает смещение в строке. |
| getEvalOrigin | возвращает место вызова eval, если функция была объявлена внутри вызова eval. |
| isTopLevel | является ли вызов вызовом из глобальной области видимости. |
| isEval | является ли вызов вызовом из eval. |
| isNative | является ли вызваный метод внутренним. |
| isConstructor | является ли метод вызовом конструктора. |
Как я уже говорил выше этот метод будет вызываться один раз и для каждой ошибки. При этом вызов будет происходить только при обращении к полю stack. Как это использовать? Можно внутри метода добавить к ошибке стек в виде массива:
Error.prepareStackTrace = function(error, stack) {
error._stackAsArray = stack.map(function(call){
return {
// ...
file : call.getFileName()
};
});
// ...
return error + ':\n' + stackAsString;
};
А затем в саму ошибку добавить динамическое свойство для получение стека.
Object.defineProperty(MyError.prototype, 'stackAsArray', {
get : function() {
// Инициируем вызов prepareStackTrace
this.stack;
return this._stackAsArray;
}
});
Так мы получили полноценный отчет, который доступен программно и позволяет отделить системные вызовы от вызовов модулей и от вызовов самого приложения для подробного анализа и обработки. Сразу оговорюсь, что тонкостей и вопросов при анализе стека может возникнуть очень много, поэтому, если хотите разобраться, советую покопаться самостоятельно.
Все изменения в API следует отслеживать на wiki-странице v8 посвященной ErrorTraceAPI.
Заключение
На этом хочу закончить, наверное для вводной статьи этого достаточно. Ну и надеюсь, что кому-то этот материал спасет время и нервы в будущем.
В следующей статье я расскажу, как сделать работу с ошибками комфортной с помощью описаных в статье подходов и инструментов.
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.
[recovery mode] Что будет значить широкополосная спутниковая технология в 100Гбит/с?

Что такое спутник с высокой пропускной способностью?
HTS — это класс спутников связи, которые превышают по меньшей мере в 2 раза (а иногда и в 20 раз) номинальную пропускную способность классического спутника на той же полосе частот. «Упаковка» большего количества битов в том же спектре частот значительно снижает стоимость передачи одного бита. Передовые технологии, используемые на спутниках ViaSat-1 и EchoStar XVII (также известный как Юпитер-1), способны обеспечить пропускную способность более чем 100 Гбит/с. Иначе говоря, эта технология позволяет передавать данные более чем в 100 раз плотнее в сравнении с обычным спутником Ku-диапазона. В самом деле, 140 Гбит/с ViaSat-1, запущенный в октябре 2011, года имел больше возможностей, чем все други коммерческие спутники связи над Северной Америкой.
Такие спутники смогут обеспечивать канал в 30-100 Гбит/с в любой точке земного шара.
Так какие же возможности открываются для пользователей, удалённых работников и предприятий в частности? Какова будет стоимость?
Преодоление стереотипов
Несмотря на технологическую шумиху, у некоторых остаётся чувство, что услуги спутниковой связи не справятся со своими задачами. Такое мнение укоренилось в основном у пользователей спутникового ТВ, которые привыкли, что картинка сильно портится или пропадает пропадает во время дождей. Чтобы минимизировать виляние погодных условий на уровень сигнала, компании применяют определённые меры.
Геораспределение
Спутниковый оператор должен позаботиться о наличии отдельных спутниковых аплинков, расположенных в географически удалённых местах. Пространственное разнесение гарантирует, что если один из аплинков глушится сильным дождём, то другой, находящийся на приемлемой дистанции, может принять нагрузку. Данный подход абсолютно не новый, он уже несколько десятилетий применяется в старом добром микроволновом радио.
Модулирование с адаптивным кодированием (ACM)
Как и пространственное разнесение, ACM — также не новая концепция. ACM было использовано в течение многих лет в других приложениях беспроводной связи, в том числе микроволновом радио. Совсем недавно технология нашла свое место в спутниковой связи. ACM адаптирует используемый порядок модуляции, а также использует код прямой коррекции ошибок. Всё это влияет на спектральную эффективность, выражаемую в битах в секунду на Герц. Корректировки происходят в зависимости от зашумленности или других нарушений на линии. Таким образом, АСМ максимизирует пропускную способность независимо от условий на линии связи, таких как шум, затухание из-за дождя и т.д.
Потребительские возможности для бизнеса
Для того что бы в полной мере оценить возможности потребительского бизнеса, давайте посмотрим на развертывание первой спутниковой потребительской услуги — служб спутникового вещания Direct-To-Home (DTH). Эти службы, включая Dish Network и DirecTV, были первыми развёрнуты на потребительском рынке в Японии, Великобритании и США.

В самом начале пути ожидалось, что спутниковая передача DTH будет ограничена только потребителями данной услуги в местах, где отсутствует наземный аналог. Сюрпризом стал феноменальный интерес городских и пригородных клиентов. Оказалось, что спутниковое телевидение было подходящим, конкурентоспособным предложением для потребителей, которые были сыты по горло кабельной компанией. Это привело к соревнованию между провайдерами спутникового телевидения и кабельными компаниями, которое длится и по сей день.
Возвращаясь к HTS, как и в случае с дебютом цифрового телевидения, было ожидание, что спутниковая широкополосная связь будет актуальна как единственная надежда для людей, которые не имеют возможности подключения наземных широкополосных услуг. Но также, как и с DTH, зачем размениваться по мелочам, если можно получить больше. Спутниковые и наземные провайдеры снова будут сражаться за сердца и умы потребителей во всем мире.
В общем, конкуренция — это хорошо. Для потребителя это создает огромные возможности, поскольку обе отрасли будут совершенствоваться и предлагать наиболее конкурентные цены и пропускную способность для потребителя.
Возможности для бизнеса
Наземные провайдеры предсказывают кончину спутниковой индустрии в корпоративных коммуникациях почти каждый год, но несмотря на это сегмент услуг спутниковой индустрии вырос на корпоративном рынке. Одна из причин — доступность спутника в любой местности, что идеально подходит, к примеру, для Ibox, который можно разместить в поезде и т.п.

Плюсы и минусы
HTS обладает большей мощностью и упаковывает больше данных в несущую частоту, чем его коллега С-диапазона. HTS обладает более узким лучом и обеспечивает отличное качество VoIP. Требуется меньшая принимающая «тарелка» (от 0,5 до 1,5 м) по сравнению с 2,5 — 4 м тарелкой С-диапазона.
Дождь сильнее повлияет на распространение высокочастотного сигнала Кu-диапазона (10,7-12,75 ГГц), чем у классического С-диапазона (3,4-5,25 ГГц). Хотя группа Ku улучшается, её покрытие не столь значительное, как у традиционных спутников, и латентность может быть значительной, что особенно заметно в онлайн-играх.
Карта покрытия спутника Ямал 202, использующего С-диапазон
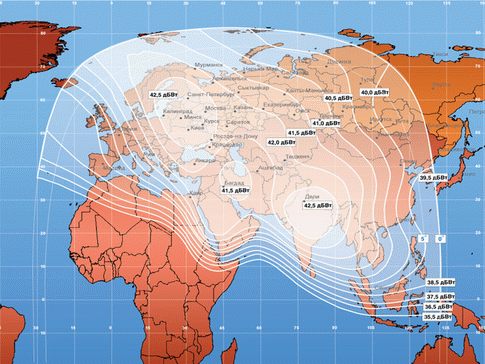
И для сравнения карта приема спутника Горизонт-2, работающего в диапазоне Кu

В Европе и США используется, как правило, Ku диапазон, в то время как Россия и Азия используют оба диапазона.
На данный момент более половины спутниковых операторов заказали (или планируют заказать) спутники HTS. «Экстрасенсы» предсказывают, что 14 миллионов пользователей и 50% терминалов на предприятиях будут пользоваться услугами спутников с высокой пропускной способностью к 2020 году.
Частично это будет происходить из экономических соображений.
Например, некоторые медиа-компании «пророчат» скатывание цены спутникового новостного канала с более чем $100000 до менее $20000 — 80%-е сокращение цены. Другим фактором (более значимым) является желание различных сегментов рынка иметь доступ к сетевым услугам в любом месте и в любое время. В этом разрезе спутниковый интернет имеет значительное преимущество.
HTS открывает множество возможностей для широкого спектра приложений в местах, которые ранее были недоступны. Сотовые операторы расширяют свою зону покрытия и касаются рынков, которые были ранее недостижимы через спутник. Это является значительным плюсом для потребителей. Однако все еще важно помнить, что, как с любой службой, Ku-диапазон — не панацея, и он подходит не для всех приложений. Это всего лишь инструмент в Вашем арсенале, который Вы можете выбрать при необходимости.
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.
Как согреться за «чужой» счет

Еще в 2011 г. Microsoft Research озвучил, что есть смысл и коммерческая выгода в идеи использования энергии, которая вырабатывается компьютерами, для отопления помещений и воды. Потребитель получает бесплатное отопление, а компания-провайдер облачного сервиса может не вкладывать средства в строительство и поддержание огромных площадок. Все в выигрыше! Потому некоторые компании начали активно внедрять эту технологию в жизнь.
Немецкая компания Cloud&Heat предлагает своеобразные «облачные обогреватели», которые представляют из себя металлический шкаф с доступом к водопроводу, который «набит» целым набором жестких дисков, плат и вентиляторов. Вы покупаете и устанавливаете такой шкаф, который стоит также, как обычная система отопления (порядка $15 тыс.), подключаете его к вентиляционной системе, водопроводу, электросети (три фазы, 400В) и интернету (не менее 50 Мбит/с). Компания оплачивает подключение к сети Интернет и затраты по обеспечению работы оборудования, а вы получаете столько бесплатного тепла и горячей воды, сколько сервер внутри шкафа может произвести в процессе работы.

Тем не менее, Cloud&Heat не стоит переживать по поводу сверх затрат, с которыми обычно ассоциируется облачная платформа. Кроме всего прочего, компания получает сильно разветвленную сеть, что помогает избежать многих проблем в работе оборудования и программного обеспечения. Cloud&Heat гарантирует обслуживание оборудования в течение 15 лет. Может показаться, что такое хранение данных не совсем надежны вариант, однако серверы скрыты внутри шкафов, а данные на дисках шифруются и резервируются.

Французская компания Qarnot проводит подобную идею, но ставит акцент на отдельном помещении, отапливаемом с помощью высокопроизводительного процессора. Технология Q.rad представляет собой электрический радиатор с прямой зависимостью температуры от объема обрабатываемых данных. После установки в доме, радиатор производит столько тепла, сколько необходимо клиентам компании Qarnot, а если тепла больше, чем нужно, можно перенаправить ресурсы научно-исследовательскому проекту BOINC Калифорнийского университета. Как и Cloud&Heat, Qarnot оплачивает электроэнергию, считая это честной сделкой, т.к. существенно экономит на инфраструктуре.
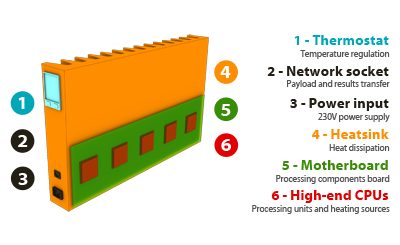
Обе компании пока находятся на ранних стадиях разработки проектов, хотя в коммерческом смысле Cloud&Heat ушли немного вперед, т.к. сфокусировались на оснащении офисов, ведь там можно разместить гораздо больше оборудования. Конечно, пройдет несколько лет прежде, чем технология полностью заменит дата-центры и обычную систему отопления, но если все планы осуществятся, останется только ждать, что подобное новшество распространится по всему миру.
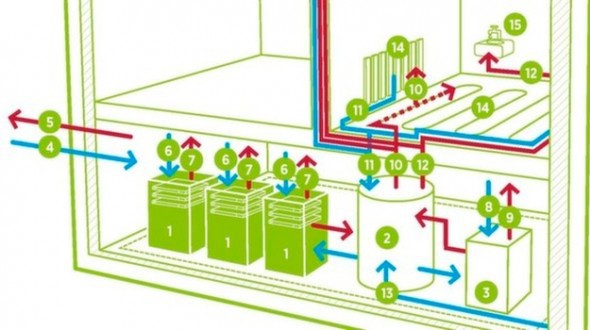
Несмотря на то, что идея отопления за счет работы оборудования очень заманчива, остается ряд вопросов, которые могут возникнуть как со стороны пользователя облачного сервиса, так и со стороны того, кто использует его тепло. Главный из них – безопасность данных. Компания Cloud&Heat утверждает, что все данные их клиентов хранятся в пределах Германии. Однако проблема в том, что наверняка знать, кого именно греет ваше «облако», невозможно. Конечно, данные зашифрованы и, по утверждению компании, прямой доступ к оборудованию имеет только персонал компании. И все же, хотелось бы знать наверняка, что в случае неполадок с интернет-подключением или электричеством в месте расположения сервера, данные будут сохранены и перенаправлены по разветвленной сети интернет-провайдера.
Другие вопросы, например, сколько пользователей имеет компания, есть ли договоренности с другими облачными провайдерами по предоставлению дополнительной мощности, если она понадобится, остаются открытыми. Потому еще рано говорить о полноценном запуске технологии, но будем надеяться, что эта инновация когда-нибудь доберется и до нас.
P.S. Пусть в Вашем доме всегда будет тепло…
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.
Inversion of Control: Методы реализации с примерами на PHP
О боже, ещё один пост о Inversion of Control
Каждый более-менее опытный программист встречал в своей практике словосочетание Инверсия управления (Inversion of Control). Но зачастую не все до конца понимают, что оно значит, не говоря уже о том, как правильно это реализовать. Надеюсь, пост будет полезен тем, кто начинает знакомится с инверсией управления и несколько запутался.
Итак, согласно Википедии Inversion of Control — принцип объектно-ориентированного программирования, используемый для уменьшения связанности в компьютерных программах, основанный на следующих 2 принципах
- Модули верхнего уровня не должны зависеть от модулей нижнего уровня. И те, и другие должны зависеть от абстракции.
- Абстракции не должны зависеть от деталей. Детали должны зависеть от абстракций.
Другими словами, можно сказать, что все зависимости модулей должны строятся на абстракциях этих модулях, а не их конкретных реализациях.
Рассмотрим пример.
Пусть у нас есть 2 класса — OrderModel и MySQLOrderRepository. OrderModel вызывает MySQLOrderRepository для получения данных из MySQL хранилища. Очевидно, что модуль более высокого уровня (OrderModel) зависит от относительного низкоуровневого MySQLOrderRepository.
Пример плохого кода приведён ниже.
Забавные баги
Однако не все баги такие. Есть и те, от которых Вы бы не стали пучками вырывать у себя на голове волосы или разбивать монитор компьютера подручными предметами. Они скорее заставят Вас посмеяться, ну или же хотя бы улыбнутся. Именно о таких багах и пойдет речь.
О, счастливчик
Май 1996 года. Самое обыкновенное рабочее утро самого обыкновенного сотрудника чикагской компании. Он решает зайти в банк, дабы узнать сколько же кровных у него на счету. А там всего лишь 900 миллионов долларов! Можете представить его выражение лица в тот момент.
Дело в том, что этот человек, на ряду с другими 825 клиентами Первого Национального банка Чикаго, стал жертвой (если можно так выразится) ошибки в системе банка — бага, благодаря которому все эти люди могли называть себя миллиардерами в течении суток. Конечно, деньги никто не украл и не сбежал на далекие острова под новым именем и накладными усами, так как средства, переведенные «счастливчикам», сильно превышали активы банка. В итоге, это была самая большая и дорогая ошибка, когда либо допущенная в американской банковской системе.
Телефон с большим эго
В 2010 году на рынке мобильных устройств появился ответ на iPhone в лице, а точнее в дисплее Windows Phone. Позднее, в 2012 году, появилась следующая версия — Windows Phone 8. Ничего катастрофического не происходило до того момента пока пользователь не решал обновить программное обеспечение. В этот момент телефон выдавал просто ошеломляющее сообщение — «Вставьте установочный диск Windows и перезагрузите Ваш компьютер». Как и куда вставлять диск телефон не уточнял. Баг произошел, так как ядро ОС Windows Phone базируется на Windows NT 1993 года. По этой причине телефон порой считает себя самым настоящим стационарным компьютером.
Вот так, даже у маленьких девайсов есть мечта стать большим и сильным.
Предательство
Siri — персональный помощник владельцев iPhone и iPad, способный общаться с ними посредством вопрос-ответ. В 2012 году в Siri завелся баг, заставивший ее предать iPhone. На вопрос «Какой телефон самый лучший в мире?» программа отвечала «Nokia Lumia 900 4G». Причиной такого странного поведения было то, что запрос передавался системе Wolfram Alpha, которая обслуживалась другой компанией. Система, в свою очередь, выдавала ответ, основанный на статистических данных и отзывах пользователей.
Естественно, данный баг был изничтожен. Теперь на сакральный вопрос программа отвечала: «Ты шутишь?» или «Тот, который у тебя в руках».
Sims 3
С самого своего старта, в 2009 году, Sims 3 обзавелась целой армией поклонников. Данная компьютерная игра-симулятор не была исключением и хранила в себе множество багов. Один из которых поклонники решили выделить. А именно, баг искажающий изображение младенца. Совершив определенные действия (одев ребенка в определенные виды одежды) можно бы понаблюдать весьма устрашающую картину.
Еще один баг — возможность создать армию младенцев. Если изменить имя ребенка, будет появляться новый, и так до бесконечности.
Маленький взломщик
Когда в семье есть маленькие дети и игровая приставка, родители ограничивают доступ своих чад к контенту «для взрослых». Например, Xbox One позволяет настраивать несколько учетных записей для разных пользователей. Одна для ребенка, другая — для родителей.
Именно так все и было в семье пятилетнего Кристофера Вильгельма фон Хасселя. Однако в марте 2014 года малыш попытался войти в учетную запись отца. После первой неудачной попытки ввода пароля юный хакер просто ввел в поле несколько пробелов, что позволило ему получить доступ ко всем отцовским играм. Он рассказал отцу, который по стечению обстоятельств работал в сфере информационной безопасности. Родитель сообщил о проблеме Microsoft, которая баг искоренила. А имя мальчика было вывешено на сайте компании Microsoft в разделе «исследователи безопасности в марте 2014 года».
Вот так Кристофер стал самым маленьким хакером в мире.
Ой, это не Вам
Как же неудобно получается, когда сообщение личного характера попадает не тому, кому следовало. Например, приглашение на романтический ужин, отправленное любимой и попавшее начальнику. Конечно, еще более странно было бы получить удовлетворительный ответ. Именно такая проблема наблюдалась среди пользователей Android, а точнее приложения Android Messaging Application. Впервые жалобы на перепутывание получателей появились еще в 2010 году, 28 июля. Однако, компания не хотела признавать существование бага вплоть до 5 января 2011 года.
Аромат свободы
В 2011 году калифорнийские тюрьмы столкнулись с проблемой нехватки места. Было принято решение условно освободить некоторое число тех заключенных, преступления которых были совершены давно и обладают низкой степенью общественной опасности. Проще говоря, украл 5 баксов — свободен, убил человека — век воли не видать.
Баг программы привел к тому, что среди прочих на свободу вышли 450 человек с тягой к насилию и около 1000 преступников, способных повторно совершить кражу и вернуться к употреблению наркотиков. К тому же, все эти добрые люди были освобождены не условно, а полностью. Поиском и возвращением блудных сыновей никто так и не занимался.
Схожая ситуация произошла в период с 2003 по 2006 год в Мичигане, где было ошибочно выпущено на волю 23 преступника. Правда, большинство из них были обычными мошенниками, не применявшими насилия.
Говорили тебе: «Гаси свет в туалете»
Следующий случай произошел в городе Ланкашир. Семья Бразертон, Найджел и Линда, решили сменить поставщика электричества со Scottish Power на Npower. На следующий месяц они получили счет на сумму не много не мало 53,480,062 фунтов стерлингов. Заметим, что предыдущий счет составлял всего 87 фунтов. Баг произошел из-за того, что сотрудник компании, подключавший дом, увидел «0» на счетчике и указал это в квитанции. Компьютер, обрабатывающий эти данные, решил что счетчик сделал максимум возможных оборотов и подсчитал их стоимость.
Глава пострадавшего семейства заявил: «Хорошо, что они не попробовали снять эту сумму с моего счета. Мало того, что я бы превысил свой кредитный лимит, так еще бы и банк обанкротился».
Синий экран смерти
Весной 1998 года состоялась презентация новой Windows 98. К компьютеру подключался сканер, который должен был обнаружится системой и начать успешно работать. Это осуществлялось посредством программного обеспечения «plug and play». Однако сразу после подключения система упала, и все увидели синий экран смерти.
В конце Билл Гейтс сказал: «Видимо, потому мы еще не продаем Windows 98».
Вы не любите котиков?
Minecraft — крайне модная и популярная игра, в которой можно построит практически все, лишь бы фантазия не подвела. И вот кому-то она послужила на славу, так как этот человек создал фонтан из котов. В игровом мире есть кошки, которые приручаются после чего следуют за игроком по земле. Если игрок оказывается слишком далеко, коты просто телепортируются к нему. Если же забраться на высокий-высокий столб, коты будут появляться нескончаемым потоком, формируя кошачий фонтан.
В ролике автор поясняет поведенческие черты игровых котов и рассказывает, как долго и старательно он пытался реализовать это чудо инженерной мысли. Это, конечно, сложно назвать багом, зато выглядит весьма забавно.
Программирование — сложный и творческий процесс. Баги — его неотъемлемая часть. Пусть же они будут Вас смешить, а не огорчать. Удачного Вам программирования, и любите котиков.
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.
пятница, 28 ноября 2014 г.
[recovery mode] Пара слов о работе на дому
Много воды лить не буду и перейду сразу к советам.
Создайте два пространства: рабочее и предназначенное для отдыха
Чтобы легче переключаться из режима работы в режим отдыха. Этот совет также упоминается в книге Remote. Лично я сделал это следующим простым образом: на моём компьютере установлены две ОС. Первая — это Windows 8, в которой я отдыхаю: путешествую по Интернету, делаю свои видеоролики, пытаюсь гонять в ралли Ричарда Бёрнса. Иногда там приходится несладко, но жизнь — вообще штука сложная.
Вторая ОС — это Kubuntu 14.04. Здесь у нас всё создано для удобной и продуктивной работы. Никакого Ричарда Бёрнса. Я создал себе шесть разных рабочих столов, каждый из которых предназначен для своей задачи, и между которыми я могу быстро переключаться через горячие клавиши. Здесь я пишу код по проектам, здесь же рядом у меня открыт браузер с кучей вкладок по текущей работе, на отдельном рабочем столе открыты окна терминалов, и так далее. В общем, когда я захожу в линукс, вся рабочая атмосфера говорит сама за себя: шутки в сторону. Пора работать.
Рабочее место
Тут просто пара маленьких советов. Применимы они, кстати, и к обычным офисам)
О той штуке, на которой мы сидим
Думаю, всем знакомо это ощущение, когда при работе в кресле у вас есть только два варианта: примкнуть к своему столу и компьютеру и работать в таком положении, в течении нескольких часов удерживая спину в напряжении. Чтобы дать спине отдохнуть, используем второй вариант: откидываемся на спинку кресла и расслабляемся. Обычно, другого варианта не предлагается в силу того, что вы не можете приблизить своё кресло в достаточной мере к столу, чтобы одновременно работать и дать отдохнуть спине. Да и сам дизайн кресел обычно не предполагает подобного подхода.
Так вот, решение проблемы заключается в том, чтобы купить себе стул, который будет поддерживать вашу осанку. Лично я нашёл себе прекрасный и дешёвый стул в Икее, сидя на котором я сейчас и пишу данную статью. Хотите верьте, хотите — нет, хоть и выглядит он довольно глупо и нелепо, но из всех кресел и стульев, на которых я работал в своей жизни, этот — самый простой и удобный. К тому же, кажется, он еще и самый дешёвый во всём каталоге. У него нет подлокотников, поэтому руки мои располагаются на столе перед клавиатурой, а сам стул, при этом, почти полностью въезжает под стол, благодаря чему я легко могу облокотиться о его спинку и практически не напрягать свою спину во время работы. И спинка его как раз разработана в таком дизайне, который сохраняет правильную осанку. А еще, когда садишься на него, он забавно пружинится)
Монитор на уровень глаз
Это снизит напряжение вашим глазам, а также дополнительно поспособствует выработке правильной осанки. Лично я использовал для этой цели второй том справочника школьника для 5-11 классов, а также первый том большой школьной энциклопедии. Книги толстые и широкие, как раз подходят для того, чтобы поставить на них монитор и приблизить его высоту к уровню глаз. Рекомендую.
График работы
Лично я разделил свой график работы на отрезки по 2-3 часа, во время которых я занимаюсь исключительно работой. То есть, когда начинается один из подобных промежутков, я начинаю жёстко пресекать все свои порывы зайти в социальную сеть, видеосервис и мессенджер, и начать там праздно бездельничать, как мы все это любим делать. Как правило, вытерпеть 2-3 часа непрерывной работы не так уж и сложно. После этого можно сделать перерыв: отвлечься на что-то, сходить в душ или прогуляться. Через какое-то время, отдохнув, можно входить в следующий свой рабочий отрезок.
Писать много не буду, я хотел просто поделиться с другими людьми парой полезных советов. Надеюсь, это принесёт кому-нибудь пользу. И всего хорошего вам, мои дорогие хабра-пользователи :)
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.
[Из песочницы] RTKLib – Сантиметровая точность GPS/ГЛОНАСС в пост-обработке
Здравствуйте!
К сожалению, я не нашел на Хабре упоминаний о замечательной библиотеке для обработки сырых измерений – RTKLib. В связи с этим рискнул написать немного о том, как с её помощью можно получить сантиметры в относительной навигации.
Цель простая – обратить внимание общественности.
Сам я только недавно начал работать с этой библиотекой и был поражен её возможностями для простых смертных. В интернете достаточно много информации о практических примерах, но хотелось попробовать самому — и вот результат.
Итак, процесс в общем виде выглядит следующим образом:
Допустим, у нас есть два ГЛОНАСС/GPS приемника, с которых мы умеем получать сырые измерения (raw data). Сырыми они называются потому, что являются первичным материалом для обработки – псевдодальности, доплер, фазовые измерения…
С помощью утилиты STRSVR из состава библиотеки RTKLib нам необходимо записать два потока данных – один от базовой станции, которая будет неподвижно стоять, и второй – от ровера, который планируем перемещать. Запись от базы желательно стартовать заранее, минут за 10-15 до записи ровера.
В моем случае база находилась на крыше здания, а с ровером выходил на улицу. Для записи использовал два ноутбука.
1) Настраиваем Input – Serial обоих ноутах, это поток от GNSS приемника.
2) Output – File, это будет у нас файл сырых измерений.
3) Пускаем базу на запись – Start и неторопливо идем на открытую местность.
Для небольшой демонстрации распечатал лист А4 с буквой H, которую хотел обвести антенной, точнее основанием под установку на штатив. Антенна TW3440 производства Канадской компании Tallysman с заказной подстилающей поверхностью 30х30 см.
4) Располагаемся на мостовой, ставим ровер на запись и пытаемся медленно обвести буковку. Хоть на ровере стоит частота выдачи 5Гц, лучше уж все сделать тщательно.
5) По окончанию обводки сворачиваемся и идем смотреть что получилось.
6) Скидываем оба файла на один компьютер и приступаем к обработке.
7) Первое – надо из сырых данных получить стандартные RINEX файлы. В этом нам поможет RTKCONV:
8) Указываем путь к файлу с сырыми данными, а так же папку, куда программа поместит RINEX, формат сырых данных, в моем случае это NVS BINR и в настройках ставим галочки GPS и GLO, остальное можно не трогать.
9) Жмем Convert и получаем файлы для ровера и потом для базы, лучше их расположить в соответствующих папках Base и Rover.
10) Далее самое интересное – пост-обработка. Открываем утилиту RTKPOST.
11) Жмем Options, вкладка Settings 1, в настройке режима указываем Kinematic для обработки относительных измерений. Ставим галочки GPS и GLO, можно потом поиграться с настройками.
12) Вкладка Output – можно выставить формат выходных данных, например NMEA.
13) Важный момент – вкладка Positions, тут надо указать координаты базовой станции, либо взять их из заголовка, либо путем усреднения за период записи. Чем точнее знаем координаты базы тем точнее будут абсолютные координаты ровера.
Для примера укажем RINEX Header Position – взять из заголовка файла.
14) Нажимаем ОК и переходим в основное окно, там в поле Rover указываем путь к RINEX файлу ровера, ну и для базы путь к соответствующему файлу. Нажимаем Execute и ждем результат. После обработки можем посмотреть результат, нажав на Plot.
15) Внизу из рисунка видно, что решений с сантиметровой точностью получено 97.3%, остальное — это плавающее решение, точность которого значительно хуже.
На этом пока все.
Если кому будет интересно, могу написать как реализовать RTK режим.
Так же неплохо бы узнать ваше мнение: в каких не очевидных приложениях можно использовать решения с сантиметровой навигацией?
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.
[Из песочницы] Код, которого нет
Около года назад Хабр захлестнула волна постов на тему "%string% в N строчек на JavaScript". Уже и не вспомню, чем все закончилось, но началось все с Excel в 30 строк. Следом появилось много и других интересных вариаций на эту тему, даже игра в ноль строк на JS, но это уже совсем другая история…
Как я ни старался придумать что-то еще более компактное — ничего не выходило. Тогда было принято решение посмотреть на проблему под другим углом. Примерно в этот момент в голове промелькнул вопрос: а можно ли «сколлапсировать» код так, чтобы его не было вообще? И тут мне позвонил Дэвид Блейн.
Я попробовал добавить немного магии и вот что у меня получилось.
«Исчезатор» кода
Задача написать код, которого… как бы нет. Еще он должен уметь что-то делать. Очевидно, что какие-либо манипуляции нужно сопроводить некоей функцией, которая бы могла интерпретировать эти манипуляции, а поэтому скрыть код вообще, увы, не выйдет, но сократить последний до пары-тройки строчек — запросто.
Многие знают или слышали, что в компьютерной типографике существуют непечатные символы, т.е. фактически невидимые. Причем это не какой-то баг или фишка, а вполне нормальное поведение — быть невидимыми. В настоящий момент одной из общепринятых и стандартизированных кодировок текста является UTF-8, она используется практически на любом современном сайте. В ней ценно и то, что там присутствует целая куча невидимых символов! Например, один из них — Zero Width Space (U+200B). Вот он: "". Видите? Нет? А он есть.
Метод Дэвида Блейна
Для желающих потрогать руками привожу ссылку на пример годичной давности: рабочее демо смотреть бесплатно онлайн. Уже потом, спустя несколько месяцев после заметки в песочнице Хабра, я случайно набрел на пост, где просматривалась эта идея (способ номер три), но без изюминки.
В моей версии кодирование производилось наипримитивнейшим образом. Минус — сильно возрастает объем файла, плюс — нужно всего два символа для кодирования. Выглядело примерно так:
var code = '1101101111110111111111111111110101101101111101111';
Спустя довольно длительное время, я вернулся к этой теме в рамках одного проекта, которым занимаюсь. Была предпринята попытка пойти дальше и начал с того, что теперь каждый символ кодируется не единицами и нулями, а четырьмя символами:
"f".charCodeAt(0).toString(16);
// "66"
//Таким образом код символа "f" - 0x0066
String.fromCharCode("0x0066");
// "f"
В итоге, имея набор из 16 символов, можно сократить избыток лишнего кода:
var Symbols = ["й","ц","у","к","е","н","г","ш","щ","з","х","ъ","ф","ы","в","а"];
//Теперь можно закодировать символ "f":
var bar = invisibleJS("f");
// bar = "ййгг";
Увеличение объема, занимаемого кодом в данном примере снизилось до 4х (4 символа, чтобы закодировать один), но по идее, если не нужен русский язык и/или какие-то другие не латинские символы, то можно добиться и 2х.
Примеры в студию
Пускай будет такой код:
alert("Hello world!");
После скармливания кода обфускатору (приводить и разбирать код не буду, в нем нет ничего интересного), на выходе получается что-то вроде:
var helloworld = "";
Обратите внимание на то, что точка с запятой находится внутри кавычек, хотя на самом деле это не так (можно проверить почти в любом текстовом редакторе, например Sublime). С одной стороны, это добавляет +5 к обфускации, вводит в заблуждение и грозит легким brain-fuck'ом, с другой — «правильный» редактор не будет применять символы влияющие на направление текста (слева-направо, справа-налево).
Вот так выглядит в результате функция декодирования:
var revealJS = function(s){return s.match(/(.{4})/g).map(function(b){return b.split('').map(function(i){return Array.apply(null,{length:10}).map(Number.call,Number).concat('abcdef'.split(''))[''.split('').indexOf(i)]})}).map(function(c){return String.fromCharCode(0+"x"+c.join(''))}).join('')}
Более чем уверен, что код мог быть лучше, меньше и элегантнее, но такой задачи не стоит в данном посте. Обращаю внимание, что в конце строки код опять идет справа-налево. В общем-то этот нюанс можно исключить, если подобрать немного другие невидимые символы.
Теперь можно «проявлять» невидимый код:
var helloworld = "";
revealJS(helloworld);
// "alert("Hello world!")"
eval(revealJS(helloworld));
// Оп!
Можно прямо отсюда скопировать в консоль или посмотреть здесь.
(Приведенный в качестве примера код «проявлятора» заточен конкретно под определенные символы, использующиеся в функции «исчезатора». Меняя эти символы местами и/или используя другие, кол-во вариантов «кодовой таблицы» взлетают далеко в бесконечность.)
У всего этого есть один большой минус: можно подглядеть выполненный с помощью eval() код. Более того, консоль даже укажет файл/строчку откуда этот код запущен:
Можно исправить это недоразумение. Если использовать все четыре символа для кодирования (о чем я говорил выше), то появляется возможность обфускации внутри обфускации. Xzibit в восторге:
// Брюки превращаются...
alert("Hello world!");
// Превращаются...
window["alert"]("Hello world!");
// Брюки...
window[revealJS("")](revealJS(""))
// ...превращаются в невидимый код:
""
Смотреть можно здесь. Кстати, никто не мешает обфусцировать код хоть трижды, хоть четырежды.
Теперь результирующий код выглядит так:
Уже лучше, но можно сделать еще кое-что. Вначале статьи я обозначил задачу скрыть код так, будто его нет. Сейчас же, можно просто открыть консоль и все сразу видно, что нехорошо. Устранить этот нюанс оказалось довольно просто: вместо eval() надо использовать :
var script = document.createElement("script");
script.innerHTML = revealJS("");
document.getElementsByTagName('body')[0].appendChild(script);
// А потом сразу же удаляем тэг, чтобы не маячил перед глазами
document.getElementsByTagName('body')[0].removeChild(script);
К сожалению, при выполнении этого кода на jsFiddle код все равно проявляется. Есть подозрение, что это каким-то образом связано с тем, что код в окне JavaScript так же оборачивается в
eval() или тот же . При тестах на локальном проекте, где нет «чудес», все работает как надо, выполняемая функция себя не проявляет:Области применения
1. For fun.
2. Средство обфускации кода.
3. Использование совместно с другими способами минификации/обфускации кода. Например Google Closure Compiler или UglifyJS.
4. Возможность скрытного общения на открытых площадках.
5. «Спящие» скрипты, «закладки» в статьях, сообщениях на форумах, досках объявлений, в контекстной рекламе, да вообще где угодно, где дают что-нибудь написать и это потом попадает в браузеры пользователей.
С последними двумя пунктами не все так однозначно, но не мог их не упомянуть. Немного раскрою мысль. При беглом просмотре, было обнаружено, что, например, Gmail и Яндекс.Почта не удаляют такие символы. Некоторые трансформируются в вид , но часть остается таки невидимой. Думаю, что в почтовых клиентах ситуация аналогичная (я проверил Thunderbird) — ничего не видно. Значит в письме можно послать скрытое сообщение, которое при «визуальном осмотре» не выдаст себя никак и при всем при этом даже в случае обнаружения непонятных скрытых символов расшифровать это сообщение сможет только тот, у кого есть алгоритм дешифрации (который, в общем-то, можно хранить в голове и написать код прямо в консоли браузера):
Привет, как дела?
А на самом деле (надо применить ф-цию
revealJS() к той части, что находится между буквой «а» и знаком вопроса):Привет как дела/*, сегодня в пять, приходи один*/?
Таким образом есть возможность скрытного общения на открытых площадках. При этом никто ничего и не заподозрит. (Разве что целенаправлено будут искать, но это другой разговор). В общем, одно из главных преимуществ (а может и единственное) заключается в том, что содержание проходит «визуальный контроль» (но и тут не все так гладко: можно сменить кодировку и все обнажится). Это как человек-невидимка и система видеонаблюдения. Кто знает, может быть весь интернет уже давно напичкан такими сообщениями? :)
Что касается спрятанных скриптов, то тут все очевидно: если в ваш браузер каким-либо образом попадет вредоносный js-код, содержащий «проявлятор» и «запускатор» (например, многие подгружают библиотеки извне, взять тот же самый jQuery, который не так давно взламывали, или какой-нибудь распространенный плагин, например AdBlock), то спрятанный на странице код с определенной степенью вероятности будет запущен. То есть в данном случае схема такая: множество разных «векторов», каждый из которых направлен по-своему и один единый «активатор», который совсем крохотный.
Спасибо за внимание.
П.С. Маленький «ништячок»: если в скрипте вначале строки поставить символ U+202E (Right-To-Left Override) в кавычках, то будет веселье. Работоспособность кода при этом сохраняется:
"";var revealJS = function(s){return s.match(/(.{4})/g).map(function(b){return b.split('').map(function(i){return Array.apply(null,{length:10}).map(Number.call,Number).concat('abcdef'.split(''))[''.split('').indexOf(i)]})}).map(function(c){return String.fromCharCode(0+"x"+c.join(''))}).join('')}
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.
Исследование виртуальных серверов с SSD дисками
В последнее время SSD накопители стали заметно дешеветь и все чаще их можно увидеть как преимущество того или иного виртуального сервера. Например, тарифов с SSD дисками сейчас — 370 штук от 65 хостеров. Естественно, SSD диски намного дороже, чем диски других типов, поэтому для сохранения низкой стоимости услуги хостеры предлагают меньшее количество места за аналогичную цену по сравнению с SATA или SAS тарифами.
Я и мой друг amoskvin из http://ift.tt/1zDhRN8 решили провести небольшое исследование дешевых тарифов на виртуальные серверы с SSD дисками. Хотелось бы поблагодарить всех хостеров, которые бесплатно предоставили виртуальные серверы для тестирования.
Для проведения тестирования была выбрана максимальная планка цены — 5 долларов за месяц. Единственное, сразу хочу заметить, что тестирование производилось в неспешном порядке и из-за колебаний курса валюты на момент публикации этой статьи планка в 5 долларов может быть немного сдвинутой, но общая идея осталась прежней: – протестировать хостеров и дешевые тарифы с SSD дисками.
DigitalOcean — довольно известный зарубежный хостер, который позиционирует себя как облачный провайдер. Он предлагает 8 различных тарифов по цене от 5 до 640 долларов. Везде используются SSD диски, на выбор большое количество дата-центров в разных странах (Великобритания, Нидерланды, США, Сингапур).
На минимальном тарифе за 5 долларов предоставляется 20 Гб жесткого диска, что очень немало за такую цену. Во всех дата-центрах используется процессор IntelXeon E5-2630L с частотой ядра 2400 МГц.
Довольно часто можно найти промо-коды для получения 10 долларов на счет, которых хватит на два месяца обслуживания по минимальному тарифу. Используется KVM виртуализация, поэтому список операционных систем, которые можно установить довольно большой.
Лондон
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| Intel Xeon E5-2630L | 2400 | 512 | 20 | 286 | 641 |
Сингапур
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| Intel Xeon E5-2630L | 2400 | 512 | 20 | 226 | 525 |
Сан-Франциско
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| Intel Xeon E5-2630L | 2400 | 512 | 20 | 864 | 935 |
Амстердам
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| Intel Xeon E5-2630L | 2400 | 512 | 20 | 318 | 1016 |
FriendHosting предлагает серверы в 4-х различных странах (Болгария, Нидерланды, США, Украина) только на SSD дисках. Минимальный тариф — 4.99 доллара за виртуальный сервер с 15 Гб SSD диска, 512 Мб оперативной памяти и одним ядром процессора 3400 МГц. Аналогично предыдущему хостеру используется KVM виртуализация.
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| QEMU Virtual | 3390 | 512 | 15 | 252 | 245 |
У ITL DC минимальный тариф стоит всего 3.5 евро и список стран полностью совпадает с FriendHosting. Отличие начального тарифа этого хостера от предыдущего — частота процессора: 2400 против 3400 Мгц. Поставить можно почти любую ОС, также есть возможность подключить собственный ISO образ.
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| QEMU Virtual | 3390 | 512 | 15 | 184 | 146 |
Mne.ru предлагает воспользоваться виртуальным сервером с SSD диском всего за 83 рубля (1.74 доллара). Оборудование находится в России и этот тарифный план предусматривает 3 Гб жесткого диска. По понятным причинам такой небольшой объем диска не позволит использовать виртуальный сервер для размещения сайтов и других аналогичных операций, а вот под специфические задачи, особенно когда нужен быстрый диск, сервер должен подойти, тем более за такую низкую цену.
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| Intel Xeon E5-2640 | 1200 | 256 | 3 | 262 | 418 |
yourserver.se — компания из Латвии имеет сайт на английском языке, однако в тикетах Вам всегда будут рады ответить на русском.
Раньше у этой компании был тариф за 2 евро в месяц, однако буквально несколько дней назад произошло обновление этого тарифа и теперь при увеличенном дисковом пространстве минимальная стоимость — 4 евро (4.99 доллара). За эту плату у пользователя оказывается 10 Гб диска и 512 Mb оперативной памяти. На выбор две локации — Латвия и Швеция. Используется OpenZV виртуализация, поэтому есть ограничения по списку ОС, которые можно установить.
Швеция
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| Intel Xeon E3-1241 | 1750 | 256 | 5 | 545 | 2373 |
Латвия
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| Intel Xeon E5-1620 | 1850 | 256 | 5 | 2042 | 498 |
У хостера VDSina минимальный тариф стоит 149 рублей (3.13 доллара) и оборудование размещается в Нидерландах. За эти деньги пользователь получает 15 Гб SSD диска, 1 ядро процессора и 512 Гб оперативной памяти, по текущему курсу доллара получается довольно выгодное предложение с точки зрения соотношения цены и ресурсов. При регистрации пользователь получает на счет 149 рублей, которых хватит на один месяц обслуживания. А использование KVM виртуализации позволяет пользователю поставить практически любую ОС: Linux, FreeBSD, Windows или любую другую из своего образа диска.
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| QEMU Virtual | 2600 | 512 | 15 | 1424 | 952 |
M4host предлагает виртуальные серверы в Латвии. Начальный тариф стоит 5 долларов и пользователю предоставляется 5 Гб SSD диска. При использовании KVM виртуализации пользователь может установить Debian, CentOS, Ubuntu или FreeBSD.
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| Intel Xeon E5-2620 | 2100 | 500 | 20 | 696 | 532 |
RackServer предлагает серверы в США и стоимость начинается от 150 рублей. Клиенту доступны 10 Гб SSD диска и 512 МБ оперативной памяти. Используется OpenVZ виртуализация, поэтому установить на сервер можно только Linux дистрибутивы.
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| Intel Xeon E5-2620 | 1300 | 512 | 11 | 557 | 3356 |
Минимальный тариф у BeriHoster с SSD диском стоит 188 рублей: оборудование размещается в России и пользователю предоставляется 10 Гб жесткого диска и 256 МБ оперативной памяти.
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| QEMU Virtual | 2270 | 256 | 10 | 380 | 553 |
JustHosting предлагает виртуальные серверы во Франции и за 120 рублей (2.5 доллара) можно получить виртуальный сервер с 10 Гб жесткого диска и 256 Мб оперативной памяти.
| Процессор | Частота | Память | Диск | IOZone W Record Size: 1MB File Size: 512MB | IOZone R Record Size: 1MB File Size: 512MB |
| Intel Xeon E5-1620 | 3700 | 256 | 10 | 282 | 208 |
В заключении могу сказать, что цены на виртуальные серверы с SSD дисками в последнее время падают из-за снижения стоимости самих дисков, однако, если Вам требуется большое количество места, то хранение информации на SSD будет не дешевым удовольствием. Однако, я почти уверен, что в будущем нас ждет отказ от медленных SATA дисков.
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.
Ресурсы для изучения Wolfram Language (Mathematica) на русском языке
На протяжении довольно долгого времени я и мои коллеги, участники Русскоязычной поддержки Wolfram Mathematica, занимались разработкой и коллекционированием полностью бесплатных и качественных ресурсов на русском языке, которые позволили бы любому желающему научиться программировать на языке Wolfram Language (Mathematica) самостоятельно.
Думаю, что пришла пора рассказать об этом на Хабрахабре, создав статью о разрабатываемой коллекции ресурсов, которая будет постоянно расширяться и пополняться, и будет служить, по сути, русскоязычным аналогом страницы "Where can I find examples of good Mathematica programming practice?" на сайте Mathematica at StackExchange.com.
Ресурсы на Хабрахабре
«Краткие уроки Mathematica» (15 видеоуроков)
Это коллекция коротких видео-лекций о программирования на языке Wolfram Language (Mathematica) с нуля. По сути, это постоянно развиваемый готовый курс программирования.
Семинары «Mathematica в действии» (13 видеоуроков)
Это коллекция подробных видео-лекций о определенных больших темах в программировании на языке Wolfram Language (Mathematica).
Блог «Mathematica в действии»
Другие полезные ресурсы
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.
84% сайтов на WordPress могут быть взломаны: что дальше?
Если вы часто читаете IT-новости, то наверняка уже устали от страшилок об очередной уязвимости, которая нашлась в популярной OS / СУБД / CMS / кофеварке. Поэтому данный пост посвящен не самой уязвимости, а наблюдению за тем, как люди регируют на неё.
Однако сначала — несколько слов о «виновнице торжества». Критическая уязвимость популярном блоговом движке WordPress была найдена в сентябре финскими специалистами из компании с весёлым названием Klikki Oy. Используя эту дыру, хакер может вести в качестве комментария к блогу специальный код, который будет выполнен в браузере администратора сайта при чтении комментариев. Атака позволяет скрытно перехватить управление сайтом и делать разные неприятные вещи под админским доступом.
Вот как легко это выглядит на практике. Заходим в блог на WordPress и вводим нехороший комментарий:
Далее мы видим, как специально сформированный комментарий позволяет обойти проверку и провести XSS-атаку:
После захвата админских полномочий злоумышленник может запускать свои коды на сервере, где хостится атакованный блог – то есть развивать атаку по более широкому фронту. Тут самое время вспомнить, что буквально недавно 800 тыс. кредиток было украдено банковским трояном, который распространялся через сайты на WordPress.
Данная уязвимость касается всех версий WordPress от 3.0 и выше. Проблема решается обновлением движка до версии 4, где такой проблемы нет.
Ну а теперь собственно о реакции. Финские эксперты по безопасности, обнаружившие уязвимость, сообщили о ней вендору 26 сентября. На момент написания этой статьи, то есть два месяца спустя после обнаружения, обновилось не более 16% пользователей WordPress (см. диаграмму на заглавной картинке поста). Из чего финские эксперты делают вывод, что все остальные 84%, то есть несколько десятков миллионов пользователей данного движка во всем мире, остаются потенциальными жертвами.
На самом деле жертв будет конечно меньше, потому что есть небольшое дополнительное условие для эксплуатации – нужна возможность комментирования постов или страниц (по умолчанию доступно без авторизации). Однако нас тут интересует именно время жизни уязвимости, и в данном случае это можно наблюдать в реальном времени — следить за статистикой обновления WordPress можно здесь. Хотя вы наверняка и так уже поняли смысл этих цифр: пока гром не грянет, мужик не перекрестится.
Мы также следим за попытками злоумышленников эксплуатировать эту уязвимость «в дикой природе». Для этого применяется сеть выявления атак на приложения на основе PT Application Firewall. Механизм выявления атак, основанный на анализе аномалий, в данном случае отработал прекрасно, и нам даже не пришлось добавлять сигнатуры. Иными словами, PT AF выявлял этот «0 day» с самого начала:
На данный момент попытки эксплуатации описанной уязвимости уже встречаются. Их пока нельзя назвать массовыми – но если у вас старый WordPress, стоит всё-таки обновиться.
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.