Воспользовавшись относительно недавно завершившимися новогодними каникулами, я занялся анализом проектов на крупнейшей международной бирже Odesk. Получившиеся результаты вкупе с описанием методики исследования и вспомогательными скриптами, думаю, будут вполне интересны широкой публике. В отличие от предыдущей прекрасной статьи на эту тему, я решил провести исследование немного с другой стороны. В первую очередь я искал ответ на вопрос «за что на odesk больше всего платят по факту и на чем мне будет лучше там зарабатывать»? Во вторую очередь хотелось оценить «с высоты птичьего полета» — что вообще представляет из себя работа на Odesk. Под катом вас ожидают:
+ примеры использованных для работы с Odesk API скриптов и описание нескольких подводных камней
+ анализ более чем 200 000 выполненных проектов на общую сумму свыше $40 000 000 USD
+ знакомство с программой для визуализации отчетов Tibco Spotfire
+ немаленькое количество разных интересных графиков
+ скандалы, интриги, расследования
Непосредственно перед анализом необходимо сделать несколько важных пояснений по сути исследования и содержимому статьи. Я — независимый веб-разработчик и консультант, в т.ч. занимаюсь фрилансом и это исследование в первую очередь делал лично для себя, чтобы лучше определить стратегические и тактические цели на год. Поэтому изначально не было цели перепахать абсолютно все данные с Odesk под всеми разрезами, данные я анализировал выборочно. Если вы захотите провести какое-либо дополнительное исследование, это достаточно легко можно будет сделать с помощью описанных инструментов. Также пожалуйста учтите, что я не являюсь профессиональным статистиком и вообще могу ошибаться в своих рассуждениях. Эта статья написана в том числе для того, чтобы совместно обсудить полученные данные и возможно посмотреть на них под другим углом. Поэтому буду рад любой конструктивной дискуссии в комментариях. Ну а теперь — поехали!
1) Подготовка к сбору данных
Odesk предоставляет довольно богатое API для работы с данными. С довольно хорошей документацией и примерами на разных языках. Все что вам необходимо для старта — получить индивидуальный ключ для работы с API. Здесь я столкнулся с первой трудностью. Все заявки модерируются и при заполнении заявки на ключ вас попросят описать суть приложения. Сначала я написал, что хочу сделать персональное исследование данных о проектах. Этого оказалось недостаточно и в процессе переписки с саппортом пришлось также написать, что я не планирую делать коммерческое приложение, не хочу зарабатывать на нем и максимум для чего собираюсь и спользовать API — для себя и для написания подобных статей. В итоге меньше чем за сутки мне все же выдали ключ и я смог заняться сбором данных.
Для удобного формирования и последующего анализа базы данных первоначально я сделал небольшую БД на MySQL из трех таблиц. В ней хранятся описания проектов, теги к ним и связи между проектами и тегами. Как вы узнаете позже в статье, в итоге этих табличек не хватило и пришлось добавить еще одну для анализа выплат по проектам с почасовой оплатой.
2) Сбор данных
Приведенный ниже скрипт на Ruby позволяет выгружать данные по проектам с интересующими вас тегами, просто перечислите их на 32 строке. При желании вы можете выгружать данные и по открытым вакансиям, заменив «completed» на «open» в 34 строке. Я выгружал базу кусками, начиная в первую очередь с интересующих меня тегов и постепенно добавляя в список попадавшие с ними заодно в базу смежные теги, которые меня заинтересовали. Таким образом данные я выгрузил с одной стороны довольно быстро, с другой — за несколько итераций захватил множество популярных тегов. Основные из них: html, html5, css, ccc3, javascript, jquery, php, wordpress, magento, drupal, python, django, ruby, ruby-on-rails, mysql, postgresql, mongodb, linux.
Данные выгружались без ограничений по времени. В итоге получилось 212 618 записей. К сожалению, при выгрузке данных только этим скриптом вы не получите данных о выплатах за проекты с почасовой оплатой, но это не беда по нескольким причинам. Во-первых, анализ проектов с фиксированной оплатой тоже интересен. Во-вторых, у нас уже будут данные по количеству почасовых проектов и их свойствам. В-третьих, бюджеты проектов с почасовой оплатой в итоге проанализировать можно и ниже вы узнаете, как это можно сделать. Пока что я опишу, как развивались события по ходу исследования. Кстати, этот скрипт учитывает и тот баг, что теги в некоторых случаях выгружаются в виде разделенной запятыми строки, а не в виде массива строк.
require 'odesk/api'
require 'odesk/api/routers/auth'
require 'odesk/api/routers/jobs/search'
require 'mysql2'
require 'sequel'
db = Sequel.connect('mysql2://XXX:XXX@127.0.0.1/odesk')
config = Odesk::Api::Config.new({
'consumer_key' => 'XXX',
'consumer_secret' => 'XXX',
'access_token' => 'XXX', # assign if known
'access_secret' => 'XXX', # assign if known
'debug' => false
})
# setup client
client = Odesk::Api::Client.new(config)
# run authorization in case we haven't done it yet
# and do not have an access token-secret pair
if !config.access_token and !config.access_secret
authz_url = client.get_authorization_url
puts "Visit the authorization url and provide oauth_verifier for further authorization"
puts authz_url
verifier = gets.strip
p client.get_access_token(verifier)
else
jobs = Odesk::Api::Routers::Jobs::Search.new(client)
search_skills = %w(ruby-on-rails)
search_skills.each do |search_skill|
params = {job_status: 'completed', skills: search_skill, paging: '0;100'}
begin
p params
results = jobs.find(params)
p results
results['jobs'].each do |job|
p job['id']
p job['date_created']
job['client'].each {|key, value| job['client_' + key] = value}
job.delete 'client'
if db[:jobs][id: job['id']].nil?
skills = job.delete 'skills'
db[:jobs].insert job
# may not exist!
unless skills.nil?
# eliminate joined tags (bug in Odesk API)
skills.map! { |s| s.split(',') }
skills.flatten.uniq.each do |skill|
s = db[:skills][skill: skill]
s_id = s.nil? ? db[:skills].insert(skill: skill) : s[:id]
db[:jobs_skills].insert job_id: job['id'], skill_id: s_id
end
end
end
end
done = params[:paging].split(';')[0].to_i + 100
params[:paging] = "#{done};100"
p done.to_f / results['paging']['total'].to_f * 100
end until results['paging']['offset'] + results['paging']['count'] >= results['paging']['total']
end
# clean too old entries
db[:jobs_skills].where('job_id IN ?', db[:jobs].select(:id).where('date_created <= ?', '2007'))
db[:jobs].where('date_created <= ?', '2007').delete
end
Пока работает скрипт, можно попить чаю. Впрочем, на ночь оставлять не придется. А если переписать его на node и запустить обработку данных в несколько потоков, то возможно все будет в разы быстрее, но в данном случае меня это не заботило.
3) Подготовка к обработке данных
Для построения визуализаций в интерактивном режиме удобно подключить напрямую к БД какую-нибудь программу для бизнес-аналитики. Я использовал Tibco Spotfire Desktop. На официальном сайте указано, что программа вроде как платная, но при скачивании ознакомительной версии никаких ограничений в ней я не нашел (хотя искал очень тщательно) и с удовольствием этим воспользовался. Также можно воспользоваться бесплатными продуктами от QlikView. Ну а Excel я изначально даже не рассматривал конкретно для этой задачи — маловато там нужных инструментов для продвинутых графиков. Пожалуй, самая продвинутая программа в этой нише из тех что я видел — Tableaue Desktop. Более интуитивная, чем Spotfire. С бОльшим количеством тонких настроек. Но она бесплатная только в течение 14-дневного trial периода, а так стоит $2000.
Прежде всего, давай взглянем на картину целиком. Напомню, что здесь и далее мы будем рассматривать только завершенные проекты. Как показывает опыт, очень часто есть ощутимая разница между проектами, за которые обещают заплатить и теми, за которые реально платят. Поэтому здесь и далее будут учитываться данные по завершенным проектам. Вот распределение бюджетов проектов с фиксированной оплатой и их количество по годам:

В 2007 году таких проектов было всего 613 с общим бюджетом $250 000. За период с 2004 по 2007 бюджеты и того меньше, так что эти данные я просто выкинул из рассмотрения. Также изначально в районе 2011-2012 годов возник на удивление большой «горб» и я увидел его причину, когда отдельно рассматривал разбивку проектов по размерам их бюджетов. В базу затесалось меньше десятка явно тестовых проектов с бюджетами от $50 000 до $1 000 000, которые в сумме дали бюджет аж почти на $5 000 000 и неслабо перекосили всю статистику. Естественно, эти аномалии я тоже выкинул из базы. Проектов с бюджетом выше $10 000 оказалось всего 92 штуки и они меня мало интересовали, поэтому их я тоже вынес за рамки исследования. Итого за 2007-2014 года получилось 103 159 завершенных проектов с фиксированной оплатой и общим бюджетом $20 000 000. Вот этот период мы далее и будем анализировать. При этом в лучший 2012 год было завершено 23 000+ таких проектов с общим бюджетом $5 000 000+
Немного забегая вперед скажу, что сначала я сильно увлекся различными графиками и до меня не сразу дошел вопрос «где деньги, Зин»? Ведь Odesk официально заявляет http://ift.tt/1t95v11, что уже к августу 2013 года заказчики потратили на бирже миллиадр долларов! На фоне этого заявления анализируемые 20 миллионов кажутся сущими крохами и никак не стыкуются с реальностью. Ведь 20 миллионов на зарплату веб-разработчикам это сущие копейки, когда речь идет о разработчиках по всему миру! Так что по этому поводу позже пришлось провести отдельное мини-расследование. Как я и обещал, сканадалы-интриги ждут вас в конце статьи :) Пока же попробуем выжать максимум из тех данных, которые получилось собрать на данный момент.
Для начала проведем количественный анализ. Карта тегов наглядно показывает самые популярные теги (по числу проектов, в которых они указаны). К сожалению, я не придумал легкого и быстрого способа построить визуализации пересечения тегов (наподобие диаграмм Венна), поэтому общая сумма проектов тут будет превышать реально число. Впрочем некоторые пересечения я высчитал вручную и они оказались довольно предсказуемыми.

Тут все понятно почти без слов. PHP рулит и педалит — 124 182 проекта. Сопутствующие html, javascript, mysql, css тоже тут как тут — у них в среднем по 45 000 проектов. Из CMS явный лидер WordPress, Joomla уступает ему аккурат в два раза. Drupal встречается в два раза реже, чем Joomla. Magento всего в 1,5 раза менее популярна чем Drupal и вообще единственная специализированная CMS для магазинов, которая видна на этой карте. Python и Ruby on Rails примерно равны по числу проектов — в районе 5000.
Если теперь посмотреть на суммарные бюджеты по тегам с разбивкой по годам, увидим примерно ту же картину, только в другом представлении:

Ну и посмотрим ради интереса на «длинный хвост» тегов:

Ну а где же здесь фреймворки типа Yii, Symfony, Zend, Laravel, AngularJS и прочие модные штучки? А их нет! По крайней мере заказчики с Odesk больше всего платят за проверенные годами повсеместно распространенные простые технологии. Предполагаю, что всякие модные крутые современные штучки это либо удел избранных, либо некритичное пожелание заказчиков (т.е. без тега), либо их выбор остается на усмотрение разработчика. Например, в самом конце данного графика, прямо перед ecommerce-consulting оказался node.js с общим бюджетом всего $155 000, что и в подметки не годится PHP с бюджетом $12 000 000, т.е. в 80+ раз больше! Этот момент был для меня откровением. Я конечно предполагал различие как минимум на порядок, но никак не мог представить, что оно так велико. Почти то же самое можно сказать и про разработчиков на Python/Ruby — их суммарные бюджеты меньше $600 000.
Впрочем, общие бюджеты — далеко не единственный интересный показатель. Ведь понятно же, что на PHP не только огромное количество проектов, но и разработчиков. При этом общий небольшой бюджет какого-то тега не означает, что разработчик будет жить впроголодь. Уверен, что множество проектов на PHP просто копеечные. Давайте посмотрим, какие навыки в среднем ценятся больше. Тут самое время оценить стоимость «среднего» проекта для того или иного тега. К сожалению, Spotfire не разрешил применить функцию медианного среднего для расчета бюджета на следующем графике. Но ограничимся хотя бы средним арифметическим, при этом сопоставим его с суммарным бюджетом:

О, вот и свежий взгляд! PHP это на самом деле черная дыра, которая поглощает разработчиков проектов со средним бюджетом $200 :) Хуже только Joomla и WordPress — причем как по числу проектов, так и по их средней стоимости. Ну оно и понятно в принципе. При этом Ruby on Rails — самые высокооплачиваемые в среднем разработчики, средний проект с их привлечением стоит $380. Если убрать из окошка PHP, четко увидим, что хорошо оплачиваются ajax — $347, flash — $323, html/xml — $294, mysql — $282.

Также я вручную с помощью SQL посчитал пересечения самых популярных тегов. Было интересно — как обстоят дела у тех, кто знает только php без js или наоборот. Как говорилось в одной КВНовской сценке: «я, конечно, догадываюсь, но хотелось бы знать точно...» Проекты с тегом php: 119 427, И БЕЗ тега javascript: 98 800. Проекты с тегом javascript: 45 179, И БЕЗ тега PHP: 24 553. Т.е. если берешься за проект с PHP — обычно, будь добр и JS знать! А вот в случае с JS дополнительно знать PHP нужно всего лишь в половине случаев. html/css уже дальше я проверять не стал, их и так все знают :)
А теперь давайте посмотрим, насколько в 2014 году были популярны проекты разных масштабов среди топовых тегов:

Обратите внимание на выдающиеся столбики с отметками $500 и $1000. Видимо это психологически важные для заказчиков уровни. Как сказал бы мой знакомый трейдер — уровни поддержки и сопротивления. Учитывая оборот проектов с этими суммами — думаю, весьма перспективным при поиске заказов будет нацеливаться именно на них. Если, конечно, вы разрабатываете на PHP/JS :) Также интересна «долина смерти» в диапазоне $500-$1000. Выбирайте, где вы хотите быть — левее или правее. Забавно, что именно начиная с $500+ на этом графике появляются html5, css3 и jquery вдобавок к обычным html, css, javascript.
Впрочем, мы можем сравнить количество и бюджеты проектов между разными технологиями. Далее будет просто безобразный с точки зрения график, который мне тем не менее весьма интересен. Он отображает в виде карты общие бюджеты проектов с определенными суммами. При этом цвет означает количество проектов. Период выборки — 2014 год. В общем и целом он подтверждает гипотезу о том, что $500, 1000$ — просто очень популярные суммы.

Ну а теперь время скандалов, интриг и расследований! :) Ведь пока что за кадром остались бюджеты проектов с почасовой оплатой и поиск призрачного миллиарда долларов. Начнем с простого — проектов с почасовой оплатой. Там конечно не получится сделать такой аккуратный анализ бюджетов как с проектами с фиксированной ценой, но хотя бы объемы оценить будет можно! Правда, понадобится дописать еще один скрипт для вытягивания данные о выплатах по таким проектам. К сожалению, для каждого проекта придется делать отдельный запрос… но что поделать! Зато у вас если что есть готовый скрипт. Кстати, в нем опять учтен подводный камень — видимо, в разные периоды времени информация в базе структурировалась различным способом и данные приходят иногда в разных структурах. Также на удивление нередко данные по старым проектам оказываются закрытыми по причине блокировки аккаунта или в связи с настройками их приватности, но общую картину получить вроде как можно.
require 'odesk/api'
require 'odesk/api/routers/auth'
require 'odesk/api/routers/jobs/profile'
require 'mysql2'
require 'sequel'
db = Sequel.connect('mysql2://XXX:XXX@127.0.0.1/odesk')
config = Odesk::Api::Config.new({
'consumer_key' => 'XXX',
'consumer_secret' => 'XXX',
'access_token' => 'XXX', # assign if known
'access_secret' => 'XXX', # assign if known
'debug' => false
})
# setup client
client = Odesk::Api::Client.new(config)
profile = Odesk::Api::Routers::Jobs::Profile.new(client)
#single hired
#job_id = '~0103a7d3ef942b98f6'
#info = profile.get_specific()['profile']['assignment_info']['info']
#two hired
#
#
db[:jobs].select(:id).where(profile_disabled: false).each do |row|
job_id = row[:id]
if db[:assignments][job_id: job_id].nil?
ap job_id
info = profile.get_specific(job_id)
# there may be error such as 'profile disabled'
if info['error'].nil?
p = info['profile']
assignments = p['assignment_info']['info'] || p['assignments']['assignment']
assignments = [assignments] unless assignments.kind_of? Array
assignments.compact.each do |a|
a.delete 'feedback'
a.delete 'feedback_for_provider'
a.delete 'feedback_for_buyer'
ap a
freelancer_id = a['ciphertext_developer_recno'] || a['as_ciphertext']
if db[:assignments][job_id: job_id, freelancer_id: freelancer_id].nil?
row = {
job_id: job_id,
freelancer_id: freelancer_id,
total_charge: a['total_charge'] || 0,
total_hours: a['tot_hours'] || 1
}
db[:assignments].insert row
end
end
else
db[:jobs].where('id = ?', job_id).update(profile_disabled: true)
ap info['error']
end
end
end
Перед запуском этого скрипта у меня было две мысли. Первая: поскольку количество выполненных проектов с фиксированной ценой и почасовой оплатой примерно равно, то вероятно и общие их бюджеты будут примерно равны. С другой стороны, Odesk выгодно отличается от российский бирж как раз возможностью почасовой оплаты и поэтому такие проекты могут быть тут популярнее. По факту бюджеты разных типов проектов оказались действительно примерно равными, это кстати меня немного удивило. С другой стороны хорошо — значимость тегов вероятно проанализирована верно. Итого общий бюджет всех проектов в базе увеличился как раз в два раза и составил примерно $40 000 000. И вот тут я крепко задумался… Как же так выходит, если
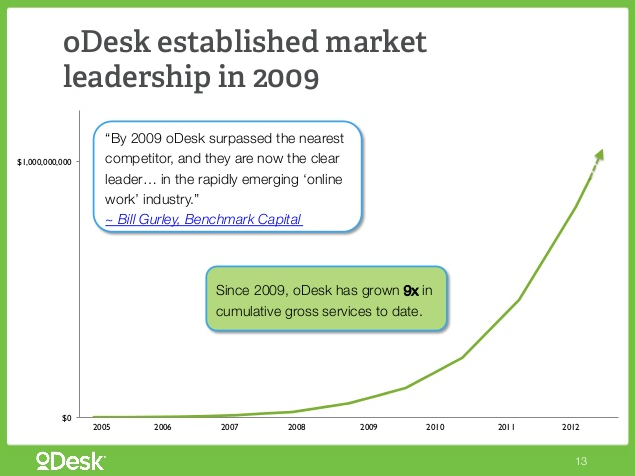
Odesk показывает красивые графики с общим бюджетом больше миллиарда за последние годы?
Ни в коем случае не хочу никого обвинять и в первую очередь хочу найти этому разумное объяснение. Может быть, я выгрузил данные только о малой части проектов? Судя по другому графику (см. слайд 23), бюджеты на веб-разработку составляют чуть ли не 30% всего оборота биржи, и PHP используется больше чем в половине проектов в этой сфере. Значит по скромным подсчетам только на проектах с PHP должно выходить около $160 000 000, а это в 4 раза больше, чем в моей базе! Может быть, API выдавало мне не все данные? Я проверил это, сделав запросы об открытых проектах с разными тегами через API и через сайт. Удивительно, но различие действительно нашлось. Хотя и не очень большое — сайт показывал примерно на 10% больше проектов, это никак не разница в 4 раз. В чем же тут дело? Может ли быть так, что недостающие деньги просто скрыты в приватных проектах, в которые заказчики напрямую приглашают исполнителей? Технически и практически это возможно. Правда я сомневаюсь, что закрытых проектов на бирже в 4 раза больше, чем открытых. Так что этот момент пока для меня остался самой большой загадкой в данном исследовании. Очень надеюсь, что знающие люди в комментариях помогут мне разобраться в этом вопросе, чтобы провести более точный анализ и вообще понять общее состояние биржи на данный момент.
В любом случае, заработать на Odesk при желании можно, и даже весьма неплохо. Так что всем заинтересованным желаю успехов, удачи и выгодного применения информации из данной статьи.
Recommended article: Chomsky: We Are All – Fill in the Blank.
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.