
В эпоху готовых отладочных плат и тысяч готовых модулей к ним, где достаточно взять пару блоков, соединить их вместе, и получить нужный результат, далеко не каждый понимает основы схемотехники, почему и как это работает, а главное — что надо делать, если это работает не так.
Как раз открылся хаб Схемотехника, так что, как говорил Бьюфорд Бешеный Пёс Таннен
Здание суда уже строят, значит пора кого-то вешать.
В этом цикле я расскажу о датчиках — как о немаловажном элементе системы управления неким объектом или тех. процессом.
Все свое повествование я буду вести касаемо практических вопросов реализации цифровых систем управления на базе микроконтроллеров.
Руководство не претендует на всеобщий обхват вопроса.
Хотя после того, как мой конспект перелез за 20 страниц текста, я решил разбить статью на следующие части:
- Часть 1. Мат. часть. В ней мы рассмотрим датчик, не привязанный к какому-то конкретному измеряемому параметру. Рассмотрим передаточные функции и динамические характеристики датчика, разберемся с его возможными подключениями.
- Часть 2. Датчики климат-контроля. В ней я рассмотрю особенности работы с датчиками температуры, влажности, давления и газового состава
- Часть 3. Датчики электрических величин. В ней я коснусь измерения электрических параметров: напряжения, тока, мощности, частоты, коэффициента мощности и искажений
Введение
В системе управления технологической установкой снятие текущих показаний некоторой величины — температуры, влажности, давления, уровня жидкости, напряжения, тока и проч. осуществляется с помощью датчиков — устройств и механизмов, предназначенных для преобразования сигнала внешнего воздействия в форму, понятную системе управления. Например, датчик влажности генерирует электрический сигнал, пропорциональный текущему значению влажности воздуха.
Как правило, датчики используются не сами по себе, а входят в состав системы управления, обеспечивая сигнал обратной связи.
 Рисунок 1. Типовая схема замкнутой системы регулирования
Рисунок 1. Типовая схема замкнутой системы регулирования
На рисунке 1 представлена типовая схема системы регулирования. Имеется сигнал задания
Xз, который сравнивается с сигналом на выходе, получаемым с помощью датчика, имеющего передаточную функцию
Wд(p). Ошибка управления подается на регулятор, который, в свою очередь, формирует сигнал управления исполнительным узлом, формирующим выходной сигнал
Y.[1]
Простой пример — центробежный регулятор частоты вращения двигателя, где датчиком является платформа с шарами, которая, вращаясь, устанавливает то или иное положение топливной рейки. Заслонка, управляемая этой рейкой, регулирует количество топлива, подаваемое на двигатель. Сигналом задания будет являться требуемое значение скорости.
1.1 Классификация датчиков
Классификация датчиков очень разнообразна. Ограничимся рамками настоящего пособия.
Все датчики делятся на два основных класса:
- Пассивные, которые не нуждаются во внешнем источнике электроэнергии, непосредственно преобразовывая входное воздействие в электрический сигнал. Примерами таких датчиков являются термопары, фотодиоды и пьезоэлектрические чувствительные элементы.
- Активные, которые требуют для своей работы внешний сигнал, называемой сигналом возбуждения. Поскольку, такие датчики меняют свои характеристики в ответ на изменение внешних сигналов, их называют параметрическими. Примерами активных датчиков являются терморезисторы, сопротивление которых можно вычислить путем пропускания через них электрического тока.
Другим важным критерием для нас является выбор точки отсчета данных. Таким образом датчики бывают
- Абсолютные, измеряемое значение физической величины которых не зависит от условий измерения и внешней среды.
- Относительные, когда выходной сигнал такого датчика в каждом конкретном случае трактуется по разному.
Ярким примером опять является терморезистор, сопротивление которого напрямую зависит только от температуры измеряемого объекта, и термопара, выходное напряжение которой зависит от разности температур между горячим и холодным концами.
При разработке радиоэлектронного оборудования важным фактором характеристик датчика также является характер выходного сигнала.
- Аналоговые датчики на выходе имеют непрерывный выходной сигнал, для снятия которого необходимо использовать аналого-цифровой преобразователь, после чего необходимо произвести преобразования значения АЦП в формат измеряемой величины.
- Цифровые датчики, информация с которых снимается с помощью различных цифровых интерфейсов. Как правило, информация доступна непосредственно в формате измеряемой величины и не требует проведения дополнительных преобразований.
- Дискретные датчики, имеющие только два варианта сигнала на выходе канала датчика — лог 0. и лог. 1. Примером такого датчика является конечный выключатель, имеющий состояния замкнут и незамкнут. Дискретный датчик может иметь несколько выходных каналов, каждый из которых находится в одном из двух состояний. Например, 12-разрядный абсолютный датчик положения.
- Импульсные датчики, формирующие импульсы выходного сигнала, амплитуда или длительность которых зависит от измеряемой величины. Например, инкрементальный датчик положения формирует на выходе код Грея. При этом, чем выше частота вращения вала датчика, тем большая частота сигнала будет на выходе, что позволит с высокой точностью определить частоту вращения вала.
2 Характеристики датчиков
Большинство датчиков имеют сложную процедуру преобразования измеряемой величины в электрический сигнал. Например, в тензорезисторном датчике давления измеряемая величина воздействует на чувствительный элемент, изменяя его сопротивление. После подачи сигнала возбуждения, падение напряжения на резисторе позволит косвенно определить его сопротивление и, на основании зависимости сопротивления от давления, вычислить измеряемую величину.
Для разработчика, датчик представляет собой черный ящик с известными соотношениями сигналов между входами и выходами.
2.1 Диапазон измеряемых и выходных значений
Диапазон измеряемых значений показывает, какое максимальное значение входного сигнала датчик может преобразовать в выходной электрический сигнал, не выходя за пределы установленных погрешностей. Данные цифры всегда приводятся в спецификации на датчик, одновременно отображая возможную точность измерений в том или иной диапазоне.
Следует понимать, что одни датчики при подаче входного сигнала больше максимальных значений просто войдут в насыщение и будут возвращать неверные данные. Другие же датчики (например датчики температуры) могут выйти из строя. В дальнейшем, для каждого типа датчика будут даны свои рекомендации.
Диапазон выходных значений датчика — это минимальное и максимальное напряжение, которое датчик способен выдать при минимальном и максимальном внешнем воздействии. Так как мы рассматриваем датчики, преобразующие входной сигнал в электрический, то диапазон выходных значений датчика будет определяться в вырабатываемом им напряжении, или пропускаемом через него токе. Одной из наших задач при подключении датчика будет согласование выходного диапазона датчика со входным диапазоном измерительного тракта.
2.2 Передаточная функция и динамические характеристики
При работе с датчиком требуется знать соотношение уровней сигналов на входе и выходе. Это соотношение, Y = f(X) будет представлять собой передаточную функцию и однозначно определять выходное состояние при определенном входном воздействии.
Передаточная функция может быть линейной и будет определяться как

(1)
Где a – наклон прямой, определяемый чувствительностью датчика и b – постоянная составляющая(т.е. уровень выходного сигнала при отсутствии сигнала на входе)
 Рисунок 2. Линейная зависимость
Рисунок 2. Линейная зависимость
Помимо датчиков с линейной зависимостью, могут быть датчики с логарифмической зависимостью, с передаточной функцией вида

(2)
Экспоненциальной:

(3)
Или степенной:

(4)
Где
k – постоянное число.
Существуют датчики с более сложными передаточными функциями. Но на то есть документация.
Однако, помимо передаточной функции нужно понимать, какими свойствами обладает датчик в динамике, т. е. насколько быстро и точно отрабатывает датчик выходной сигнал при быстром изменении входной величины. Практически каждый реальный датчик имеет в себе накопитель энергии — конденсатор, массу и т. п. Рассмотрим поведение датчика, динамические характеристики которого описываются уравнением первого порядка:

(5)
В теории автоматического управления существует два тестовых входных сигнала. Это единичная функция — подача в нулевой момент времени единицы, и дельта-функция — подача сигнала бесконечной амплитуды и бесконечно малой длительности.
 Рисунок 3. Единичная и дельта функции
Рисунок 3. Единичная и дельта функции
Безынерционный, то бишь идеальный датчик в точности повторит форму входного сигнала. Реальный датчик, описанный формулой (5) выдаст следующую реакцию:
 Рисунок 4. Реакция апериодического звена первого порядка на тестовые сигналы
Рисунок 4. Реакция апериодического звена первого порядка на тестовые сигналы
Следует отметить, что значение на выходе датчика будет соответствовать поданному на входе только после завершения переходного процесса, которое будет длиться 3-4
τ, где
τ — постоянная времени нашего звена. При
t=1τ, выходное значение достигнет

Нетрудно посчитать, что при
t = 2τ выходное значение составит 86%, а при
t = 3τ — 95% и переходный процесс будет считаться завершенным.
Таким образом нужно понимать, что, например, тот же датчик температуры будет реагировать на изменение температуры окружающей среды с некоторым запаздыванием из-за того, что между датчиком и окружающей средой имеется корпус, который должен поглотить тепло и нагреться. На это требуется время.
Разумеется, инерционные датчики могут описываться более сложными уравнениями, например представляться апериодическими звеньями второго порядка, иметь задержку реакции и т. д. Особенности поведения таких звеньев подробно описаны в [1].
2.3 Точность, нелинейность
Одной из важных характеристик датчика является его
точность в диапазоне измеряемых величин. Выходной сигнал датчика соответствует значению измеряемой величины с некоторой достоверностью, называемой погрешностью.
Например, датчик температуры имеет точность ±2 градуса. Это означает, что при реальной температуре измеряемого объекта в 100 градусов, допустимые показания данного датчика температуры находятся в пределах 98 – 102 градусов.
Зачастую, это объясняется
нелинейностью датчика в измеряемом диапазоне. В зависимости от текущего диапазона измерения, коэффициент наклона передаточной функции изменяется в некоторых пределах. При этом, в спецификации указываются либо кривые изменения точности по диапазону, либо худшие показатели нелинейности в том или ином диапазоне.
Кроме того, некоторые датчики имеют эффект гистерезиса, когда для одного и того же входного сигнала после возрастания и убывания значения выходного сигнала получаются разными. Типичной причиной гистерезиса является трение и структурные изменения материалов. Наибольшему эффекту гистерезиса подвержены датчики на основе ферромагнитных материалов.
Некоторые датчики требуют проведения калибровки для повышения точности. Для линейного датчика необходимо с заведомо известной точностью определить показания в двух точках, находящиеся на разных концах рабочего диапазона. Можно воспользоваться более точной аппаратурой, можно воспользоваться эталоном (например черное тело, эталонный килограмм и т. п.). Точность после калибровки естественно не сможет превышать точность эталона.
2.4 Чувствительность датчика, разрешающая способность и мертвая зона
Мертвая зона датчика — это нечувствительность датчика в определенном диапазоне входных сигналов. В пределах этой зоны выходные показания некорректны.
Для примера на рисунке 2 показания выходной величины для всех значений от 0 до x0 не определены. Такой особенностью грешат, например, некоторые датчики тока, имеющие нулевое напряжение на выходе при токах меньших, к примеру, 10мА.
Во всем остальном диапазоне имеет место определенная
чувствительность датчика, т. е. насколько силен прирост выходного сигнала на изменение входного сигнала. т. е. чувствительность определяется следующей формулой:

Для линейного датчика, чувствительность будет постоянной на всем измеряемом диапазоне.
Разрешающая способность показывает, насколько малое изменение измеряемой величины способно вызвать изменение выходного сигнала. Например, какой-нибудь инкрементальный датчик положения имеет разрешающую способность в 1 градус. Аналоговые датчики обладают бесконечно большим разрешением, так как в их выходном сигнале нельзя определить отдельных ступеней его изменения.
3 Способ подключения датчиков
В зависимости от типа датчика, подключается он к измерительному тракту по разному.
Подключение пассивного датчика
Так как пассивный датчик без посторонней помощи в ответ на внешнее воздействие самостоятельно вырабатывает для нас электрический сигнал, нам этот сигнал нужно считать.
В зависимости от того, будет ли наш датчик источником тока или источником напряжения, способ подключения будет отличаться.
К примеру, термопара является источником напряжения — напряжение на выходе не зависит от величины выходного тока (в разумных пределах конечно). Наша задача — измерить вырабатываемую ЭДС. Так как измерительный тракт будет иметь некоторое конечное сопротивление, схема подключения будет следующей:
 Рисунок 5. Подключение источника напряжения к АЦП
Рисунок 5. Подключение источника напряжения к АЦП
Если
Radc будет много больше внутреннего сопротивления
r, тогда падение напряжения на нем будет стремиться к нулю и напряжение на входе АЦП будет стремиться к значению ЭДС.
Во второй части я подробно рассмотрю термопару, как один из самых точных и быстродействующих датчиков.
Другой случай, если наш датчик является источником тока, т.е генерируемое им напряжение зависит от пропускаемого через нагрузку тока.
Подключение датчика аналогично:
 Рисунок 6. Подключение источника тока к АЦП
Рисунок 6. Подключение источника тока к АЦП
Однако, сопротивление нагрузки источника тока теперь должно стремиться к нулю. Для этого, датчик шунтируется резистором необходимого сопротивления, превращая тем самым, источник тока в источник напряжения:
 Рисунок 7. Правильное подключение источника тока к АЦП
Рисунок 7. Правильное подключение источника тока к АЦП
Сопротивление резистора
Rш рассчитывается как частное от деления максимального напряжения, подаваемого на вход АЦП на максимальный ток, который способен выдать датчик

Наиболее яркий представить такого датчика — датчик тока.
ВНИМАНИЕ: датчики, имеющие схему замещения в виде источника тока, следует обязательно шунтировать сопротивлением и не допускать обрыва цепи шунтирования при наличии сколь угодно малого входного воздействия. В противном случае, тот же датчик тока генерирует на свободных клеммах вторичной обмотки напряжение в киловольты до пробоя схемы измерения или самого датчика. Современные датчики тока тестируют на напряжении 1кВ и более, так что получить на выходе 2-3кВ, а еще попасть в них пальцем — не самая сложная задача.
Подключение активного датчика
Рассмотрим активные датчики, представляющие собой переменное сопротивление. В частности это терморезисторы, тензорезисторы и прочие подобные датчики. Чтобы сопротивление датчика измерить, его необходимо подключить к источнику тока и определить падение напряжения на нем:
 Рисунок 8. Подключение датчика к нерегулируемому источнику тока
Рисунок 8. Подключение датчика к нерегулируемому источнику тока
Источник тока вырабатывает ток постоянного значения известной величины. Тогда, выходное напряжение будет определяться по формуле:

(7)
Например, рассчитаем выходное значение напряжения при токе источника 10мА если наш датчик изменяет сопротивление от 0,1кОм до 1 кОм. Тогда максимальное выходное напряжение будет равно

(8)
Что вполне соответствует требуемому значению напряжения для аналоговой системы управления на базе операционных усилителей.
Где взять источник тока? Бывает так что он встроен в сам микроконтроллер. Например в микроконтроллерах ADuCM360/361 есть два встроенных источника тока 0,01-1мА. Правда там у них диагностическая задача — подавая малый ток через цепи датчика можно убедить в его наличии и исправности.
Конечно, нам привычнее использовать источник напряжения с делителем:
 Рисунок 9. Подключение датчика к источнику напряжения с делителем
Рисунок 9. Подключение датчика к источнику напряжения с делителем
Если говорить на чистоту, то цепочка U-R1 образует тот же самый источник тока, только его параметры зависят от нагрузки —
Rд. Напряжение на выходе будет определяться по следующей формуле:

(9)
И тут всплывает главная проблема такого метода — от сопротивления нашего датчика в знаменателе не избавишься никак и показания становятся нелинейными, в отличие, кстати, от первого варианта.
Встает вопрос — каким должно быть сопротивление
R1? Оно должно обеспечивать максимальный диапазон выходного напряжения. т. е. при известных значениях минимального и максимального сопротивления датчика
Rд1 и
Rд2,
abs(Uвых1 — Uвых2) -->max
С другой стороны, максимальное выходное напряжение у нас ограничено входными цепями измерительного устройства. Например, на вход микроконтроллера с питанием 5В необходимо подать напряжение, к примеру, не более 2,5В. Отмечу, что если максимально возможное напряжение, подаваемое на вход АЦП меньше напряжения питания, то мы сможем его туда подать.
Если наш датчик изменяет сопротивление от 0,1кОм до 1 кОм, то примем сопротивление резистора R1 равное верхней границе сопротивления датчика. Тогда Uвых сможет изменяться в пределах от 1/11Uвх до 1/2Uвх. В абсолютных цифрах данного примера — от 0,45 до 2,5В. И такими значениями мы используем (2,5-0,45)/2,5 = 82% всего диапазона АЦП, что довольно неплохо.
Еще датчик можно воткнуть в состав измерительного моста и измерять разницу напряжений в его плечах:

Рисунок 10. Датчик в составе измерительного моста
В этом случае мы работаем с дифференциальным АЦП, измеряя разность потенциалов Uab. Она будет равна:
 (10)
(10)
Причем сопротивление резистора R1 может быть таким, чтобы Uab могло быть и отрицательным. Существуют датчики, внутренняя схема которых уже представляет собой балансный мост с необходимыми характеристиками. Позднее я рассмотрю примеры таких датчиков.
Существуют более удобные в использовании датчики. Они выдают необходимый аналоговый сигнал и без танцев с резисторами. Например, аналоговый датчик влажности HIH-4010-004 — трехвыводной корпус, 5В питание, линейный выход. Подключается это чудо так:

Рисунок 11. Подключение датчика влажности HIH-4010-004
Два провода к источнику опорного напряжения, выход — к АЦП микроконтроллера.
Подключение цифровых датчиков по стандарту 1-Wire
1-Wire это двунаправленныя низкоскоростная цифровая шина передачи данных, требующая всего два провода — информационный провод и землю. Шина достаточно проста в использовании, поддерживает паразитное питание устройств от линии и позволяет подключать параллельно множество однотипных устройств вроде датчиков температуры(всеми любимыми DS18B20), или микросхем идентификации (iButton).
Паразитное питание организовывается следующим образом:
 Рисунок 12. Паразитное питание устройств шины 1-Wire
Рисунок 12. Паразитное питание устройств шины 1-Wire
А это обычное активное питание устройства, когда до источника рукой подать.
 Рисунок 13. Питание устройства 1-Wire от внешнего источника
Рисунок 13. Питание устройства 1-Wire от внешнего источника
Количество подключенных параллельно датчиков фактически ограничено лишь параметрами линии.
Возможно горячее подключение и идентификация на ходу. Причем вычислительная сложность алгоритма идентификации
O(log n)
Более подробно с этим протоколом мы поработаем во второй части.
А пока, про сам протокол можно почитать по классической ссылке:
http://ift.tt/1jcu96W
Подключение цифровых датчиков по стандарту I2C(Twi)/SMBus
Если 1-Wire требовала один провод данных, то эта шина, исходя из названия Two-Wire Bus — два.
Один из проводов — SCL будет тактирующим, по второму — SDA, полудуплексом будут передаваться данные.
Шина с открытым коллектором, следовательно обе линии необходимо подтянуть к питанию. Датчик будет подключаться следующим образом:
 Рисунок 14. Подключение датчиков по I2C
Рисунок 14. Подключение датчиков по I2C
Общее количество устройств, которые можно подключить к шине I2C — 112 устройств при 7-разрядной адресации. Каждому устройству на деле выделяется два последовательных адреса, младшим битом выставляется режим — на чтение или запись. Есть строгое требование по емкости шины — не более 400пФ.
Общеупотребительные значения скоростей — 100 кбит/сек и 10 кбит/сек, хотя последние стандарты допускают и скоростные режимы в 400 кбит/сек и 3.4мбит/сек.
Шина может работать как с несменяемым мастером, там и с передачей флага.
Огромное количество информации по протоколу можно найти по этой ссылке:
http://ift.tt/1HXYCmL
Подключение цифровых датчиков по стандарту SPI
Требует как минимум три провода, работает в режиме полного дуплекса — т.е. организует одновременную передачу данных в обе стороны.
Линии связи:
- CLK — линия тактового сигнала.
- MOSI — выход мастера, вход слейва
- MISO — вход мастера, выход слейва
- CS — выбор чипа (опционально).
Одно из устройств выбирается мастером. Оно будет отвечать за тактирование шины. Подключение осуществляется перекрестным образом:
 Рисунок 15. подключение по SPI и суть передачи
Рисунок 15. подключение по SPI и суть передачи
Каждое устройство в цепи содержит свой сдвиговый регистр данных. С помощью сигналов тактирования, спустя 8 тактов содержимое регистров меняется местами, тем самым, осуществляя обмен данными.
SPI — Самый скоростной из представленных интерфейс передачи данных. В зависимости от максимально-возможных частот тактирования скорость передачи данных может составлять 20, 40, 75 мбит/сек и выше.
Шина SPI позволяет подключать устройства параллельно, но здесь возникает проблема — каждому устройству требуется своя линия CS до процессора. Это ограничивает общее количество устройств на одном интерфейсе.
Главная сложность в настройке SPI — это установить полярность сигнала тактирования. Серьезно. Настроить SPI не просто, а очень просто.
Коротко и ясно об SPI с описанием периферийных модулей SPI для AVR и MSP430 можно прочитать здесь
http://ift.tt/1HXYCmO
4 Снятие показаний с датчиков
Пора бы уже прочесть с наших датчиков хоть какую-то информацию.
В зависимости от способа подключения датчика и его типа возможны различные способы снятия показаний. Следует отметить, что некоторые датчики, например цифровые датчики, или датчики состава газа, требуют предварительного запуска режима измерения, который может длиться некоторое время.
Таким образом, процесс измерения состоит из двух тактов — такт измерения данных и такт снятия данных. При организации программы можно пойти по одному из следующих вариантов:
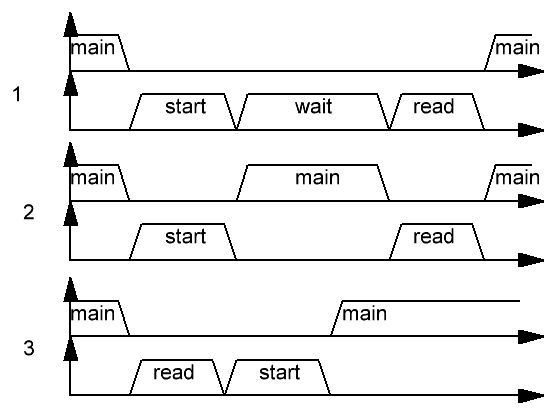 Рисунок 16. Процесс считывания показаний с датчика
Рисунок 16. Процесс считывания показаний с датчика
Рассмотрим каждый вариант по отдельности и набросаем скелеты:
Вариант 1. запустили режим измерений, подождали, считали.
Вариант притягателен своей простотой, однако за ней кроется проблема — во время ожидания выполнения измерений микроконтроллер нагло простаивает, не выполняя задач. В большинстве систем автоматики такой режим — непозволительная роскошь.
В коде это будет выглядеть следующим образом:
Sensor.Start();//запустить процесс измерений
delay(MINIMAL_SENSOR_DELAY_TIME);//ожидаем завершения процесса
int var = Sensor.Read();//считываем данные
Вариант 2. запустили режим измерений, вернулись к другим задачам, по прошествии времени сработало прерывание, считали данные.
Один из лучших вариантов. Но наиболее сложный:
void Setup(){
TimerIsr.Setup(MINIMAL_SENSOR_DELAY_TIME);//настраиваем прерывание по таймеру с необходимой периодичностью
int mode = START;//переменная состояния
Sensor.Start();//запускаем процесс измерений в первый раз
}
TimerIsr.Vector(){//обработчик прерывания по таймеру
if (mode == START{
mode = READ;
var = Sensor.Read();//если датчик был в режиме измерения, считываем данные
}
else
{
mode = START;
Sensor.Start();///если датчик был в режиме считывания данных, запускаем новый цикл измерений
}
}
Выглядит неплохо. позволяет варьировать время между циклами измерений и циклами считывания. например, датчик состава газов должен успеть остыть после предыдущих измерений, либо успеть нагреться во время измерений. Это разные периоды времени.
Вариант 3: Считали данные, запустили новый виток.
Если датчик позволяет после считывания данных запускать новый цикл измерений, то почему бы и нет — сделаем все наоборот.
void Setup(){
TimerIsr.Setup(MINIMAL_SENSOR_DELAY_TIME);//настраиваем прерывание по таймеру с необходимой периодичностью
Sensor.Start();//запускаем процесс измерений в первый раз
}
TimerIsr.Vector(){//обработчик прерывания по таймеру
var = Sensor.Read();//считываем данные
Sensor.Start();///запускаем новый цикл измерений
Отличный способ сэкономить время. и знаете что — такой метод отлично работает и без прерываний. Цифровые датчики хранят вычисленное значение вплоть до отключения питания.А с учетом того, что считывать сигналы с датчика влажности ввиду его инерционности в 15 секунд часто и не требуется, можно и вовсе сделать так:
void Setup(){
Sensor.Start();//запускаем процесс измерений в первый раз
while(1){
//много всякой остальной рутины
var = Sensor.Read();//считываем данные
Sensor.Start();///запускаем новый цикл измерений
}
}
К сожалению, первый метод поголовно используется в библиотеках и примерах для Arduino, не позволяет этой платформе правильно использовать ресурсы микроконтроллера. Зато он проще в написании и отладке.
4.1 Работа с АЦП
Имея дело с аналоговыми датчиками имеем дело с АЦП. В данном случае рассматривается АЦП встроенный в микроконтроллер. Так как АЦП является по сути тем же датчиком — преобразует электрический сигнал в информационный — для него справедливо все что описано выше в разделе 2. Главными характеристиками АЦП для нас являются его разрядность, опорное напряжение и быстродействие. При этом, выходным значением АЦП преобразования будет некоторое число, которое необходимо перевести в абсолютное значение в единицах измеряемой величины. Ниже, для отдельных датчиков будут рассмотрены примеры таких расчетов.
4.1.1 Опорное напряжение
Опорное напряжение АЦП — это напряжение, которому будет соответствовать максимальное выходное значение АЦП. Опорное напряжение подается от источника напряжения, как встроенного в микроконтроллер, так и внешнего. От точности этого источника зависит точность показаний АЦП. Типовое опорное напряжение встроенного источника равняется напряжению питания или половине напряжения питания микроконтроллера. Могут быть и другие значения.
4.1.2 Разрядность АЦП и чувствительность
От разрядности АЦП зависит его чувствительность. Чем больше промежуточных ступеней выходного напряжения, тем выше будет чувствительность.
Допустим, опорное напряжение АЦП
Uоп. Тогда, N-разрядный датчик, имея 2N возможных значений, имеет чувствительность

(11)
Таким образом, для 12-разрядного АЦП и опорного напряжения в 3,3В его чувствительность составит 3,3/4096 = 0,8мВ
Так как наш датчик также обладает определенной чувствительностью и точностью, будет неплохо, если АЦП будет обладать лучшими показателями.
4.1.3 Быстродействие АЦП
Быстродействие АЦП определяет, насколько быстро могут быть получены показания. АЦП последовательного приближения требуется определенное количество тактов, чтобы снять показания. Чем больше разрядность, тем больше тактов и меньше. Быстродействие АЦП измеряется в количестве семплов данных в секунду. Для каждого варианта разрядности возможно рассчитать свое быстродействие. В технической документации обычно указывается диапазон минимального-максимального быстродействия при максимальной частоте тактирования АЦП.
4.2 Цифровые датчики
Главное преимущество цифровых датчиков перед аналоговыми — они предоставляют информацию об измеряемой величие в готовом виде. Цифровой датчик влажности вернет абсолютное значение влажности в процентах, цифровой датчик температуры — значение температуры в градусах.
Управление датчиком осуществляется с помощью имеющихся в нем регистром в форме вопрос-ответ. Вопросы следующие:
- Запиши в регистр A значение B
- Верни значение, хранящееся в регистре C
В ответ датчик, соответственно, либо записывает необходимые данные в регистр, производя настройку параметров или запуск какого-то режима, либо передает контроллеру измеренные данные в готовом виде.
На этом я закончу общий материал. В следующей части мы рассмотрим датчики HVAC с примерами.
После датчиков пойдет рассмотрение исполнительных устройств — там довольно много интересного с точки значения теории автоматического управления, а потом доберемся и до синтеза и оптимизации регулятора всего этого безобразия.
Список полезной литературы:
- Бессекерский В.А., Попов Е.П. Теория систем автоматического управления / В.А. Бесссекерский, Е.П. Попов — Изд. 4-е, перераб. И доп. — Спб., Профессия, 2007. — 752с.
- Датчики: Справочное пособие / В.М. Шарапов, Е.С. Полищук, Н.Д. Кошевой, Г.Г. Ишанин, И.Г. Минаев, А.С. Совлуков. — Москва: Техносфера, 2012. — 624 с.
- Г. Виглеб. Датчики. Устройство и применение. Москва. Издательство «Мир», 1989
- Современные датчики. Справочник. ДЖ. ФРАЙДЕН Перевод с английского Ю. А. Заболотной под редакцией Е. Л. Свинцова ТЕХНОСФЕРА Москва Техносфера-2005
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.