
Для большинства людей Джозеф Любин – ведущий мыслитель в стремительно развивающейся области цифровых валют. Для меня он был человеком, с которым я провёл первую свою сделку по обмену биткоинов, и человеком, привыкший говорить большие вещи ровным и скромным голосом.
Зимой 2014 года он позвал меня с собой на биткоин-конференцию в Майами, чтобы рассказать о новом проекте Ethereum, который он с единомышленниками из Канады запустил за несколько месяцев до этого. Когда он объяснил мне суть проекта, он не скупился на прогнозы: «Мы заменим страховые компании и Уолл Стрит».
Список продолжал расти. Онлайн-сервисы по распространению фильмов вроде Netflix и Hulu. Игровые платформы вроде Xbox и Sega Genesis. Мессенджеры вроде Twitter. Пенсии, обмены валют, системы голосования, управление интеллектуальной собственностью, трастовые фонды. Если верить Любину, то всё – реально всё, что мы делаем через интернет или по другим цифровым каналам, претерпит радикальные изменения.
Рассказанная им идея с тех пор завладела умами энтузиастов цифровых валют. Идея в том, что технология, обеспечивающая безопасные транзакции в сети биткоин, и делающая их прозрачными, очень быстрыми и нецензурируемыми, и не требующими доверия другим сторонам, может использоваться для обработки более сложных сделок и хранить любую цифровую информацию в интернете.
За последний год эта теория развивалась очень непоследовательно и неорганизованно. Уже существуют распределённая система доменных имён, цифровой нотариат, не требующий услуг третьей стороны, и сервисы по управлению финансовыми контрактами через децентрализованные эксроу-аккаунты. Некоторые эксперименты проходят в самой сети биткоин. Другие проекты, как и Ethereum, запустили новые сети или подключаются к альтернативным цифровым валютам – клонам биткоин. Многие начинания уже получили финансирования. В январе Spark Capital и израильская фирма венчурных инвестиций Aleph профинансировали стартап Colu на $2,5 миллиона.
На встречах и конференциях присутствует осязаемое ощущение безграничных возможностей, и что деньги – лишь первое и самое скучное применение технологии биткоин.
При всём разнообразии проектов, они стремятся изменить один неприятный тренд – отсутствие «правдивых агентств» в интернете. Все данные, создаваемые в онлайне и все операции обрабатываются централизованными серверами, большинство из которых находится в дата-центрах, управляемых корпорациями и правительством. Мы зависим от них во всём. Они хранят наши емейлы, отправляют их, проверяют нашу личность при заходе на сайты и в мобильные приложения. Они отслеживают наши покупки и обрабатывают платежи.
Номинально наши данные принадлежат нам, но для получения доступа к ним и управления ими нам нужны сопровождающие лица, чтобы попасть из одной цифровой комнаты в другую. Мы не владеем своими данными, а лишь навещаем их время от времени.
Ник Забо [Nick Szabo] (чьи теории по цифровым контрактом и умной собственности заслужили ему такое уважение в среде поклонников цифровых валют, что его постоянно обвиняют в создании сети биткоин), суммирует проблему в своём блогпосте:
У всех этих машин архитектура была разработана для того, чтобы её контролировал один человек или иерархия из людей, знающих и доверяющих друг другу. Они могут читать, изменять, удалить или блокировать все данные на этих компьютерах. С современными веб-сервисами мы полностью доверяем, то есть полностью зависим, от компьютера, а точнее – от людей, имеющих к нему доступ, инсайдеров, хакеров, в вопросах выполнения наших заказов, обработки платежей и т.п. Если кто-то на другом конце захочет игнорировать или подделать ваши инструкции, их не остановят системы защиты – только ненадёжные и дорогие организации, чья юрисдикция обычно заканчивается на границе страны.
Долгое время всё это воспринималось как должное. Если наш цифровой мир можно свести к набору записей, которые мы обновляем и переносим с места на место, то защита этих записей от повреждения жизненно важна. Традиционное решение – ограничить доступ до небольшой группы доверенных лиц. В большинстве случаев мы доверяем интернет-сервисам, предполагая, что их приоритеты совпадают с нашими, и что у нас есть возможность призвать их к ответу за их проступки.
Но всё больше и больше приоритеты этих организаций не совпадают с приоритетами людей, которым они должны служить. Помните, когда Facebook переключил свои цифровые переключатели в соцсети и запустил всеобщий психологический эксперимент на своих пользователях?
Столкнувшись с нерешаемой проблемой, мы остановились на наименее плохом из возможных варианте – передаче ответственности за наши данные как можно меньшему количеству лиц. Ведь глупее, чем доверять наши ценные цифровые записи некоей центральной власти, будет только доверить их кучке неизвестных лиц.
Но именно это и делает биткоин: публичная база данных, которую могут видеть все, к которой все могут делать добавления, и которую никто не может уничтожить.
С чего нам доверять биткоину, а точнее, технологии, стоящей за ним? Потому, что она сразу подразумевает, что все стороны сделки нечестны, и при этом заставляет всех следовать правилам.
Когда люди говорят о технологии биткоин, они имеют в виду две вещи. Первая – всемирная база данных, записывающая транзакции и линейно растущая по кусочкам под названием «блоки», формирующими «цепочку блоков». Вторая – сеть участников, именуемых майнерами, которые представляют собой компьютеры (и их владельцев), добавляющих блоки к сети.
Сначала взглянем на цепочку блоков. Если у вас есть биткоины, это значит, что в цепочке есть запись, содержащая численное значение («монеты»), и половину цифровой подписи. Цифровая подпись – это криптографическая задачка, которую можете решить только вы, потому что только у вас есть соответствующая половинка. Это ваш «приватный ключ», и если у вас есть биткоин-кошелёк, то и то, что находится в нём.
Желая потратить биткоины, вы делаете запрос на добавление новой записи в цепочку блоков. Новая запись относится к тем биткоинам, которые вы хотите потратить – она указывает на предыдущую транзакцию, благодаря которой вы получили эти монеты. Она доказывает, что вы действительно ими обладаете, поскольку ваша половина подписи решает криптозадачку, и добавляет новую подпись к биткоинам, которую может дополнить только новый владелец биткоинов. Когда он захочет их потратить, процесс повторится.
Поэтому, цепочка блоков – это всего лишь длинная цепь транзакций, каждая из которых ссылается на предыдущую запись в цепи. Но пользователи биткоин не обновляют цепочку блоков напрямую. Для передачи монет кому-либо, вам надо создать запрос и распространить его по сети peer-to-peer. После этого он окажется в руках майнеров. Они обрабатывают запросы и проверяют корректность подписей, и что количество биткоинов достаточное для проведения транзакции. Они запихивают новые записи в блок и добавляют его в конец цепочки.
Все майнеры работают независимо друг от друга, со своей версией цепочки блоков. Заканчивая новый блок, они распространяют его остальным участникам, которые проверяют его, принимают, и добавляют к концу цепочки и продолжают работу уже с этой точки.
Всё это будет работать, только если майнеры договорятся, как должна выглядеть самая новая версия цепочки блоков. Но так как они не знакомы друг с другом, у них нет причин доверять друг другу. Что остановит майнера, если он захочет смухлевать с ранними записями в цепочке и отменить платежи?
Стратегия, продуманная Сатоси Накамото (псевдоним архитектора биткоин) для достижения консенсуса в этой системе, считается прорывом в распределённых вычислениях.
«С 80-х годов существовали алгоритмы консенсуса, где вы достигали его, предоставляя журналы работы нескольких компьютеров, работавших в одной сети»,- говорит Пол Сноу, основатель Factom, сервиса, пакующего данные и отправляющего их в цепочку блоков биткоин. Но эти системы успешно работали при условии их сотрудничества и лояльности.
Биткоин заменяет лояльность математической уверенностью. Учитывая криптографическое доказательство, которое нужно привести для проведения транзакции, мы уже уверены, что биткоины могут потратить только те люди, которые их имеют. Но майнер также может быть уверен, что другие майнеры не меняют записи в цепочке, поскольку биткоин невозможно откатить назад.
Процесс добавления нового блока в цепочку очень труден. Всем участникам приходится задействовать большие вычислительные мощности, а значит, и электричество, чтобы прогонять новые данные через набор расчётов, называющихся хэш-функциями. Только после окончания этой работы блок можно добавить в цепочку так, чтобы удовлетворить всех остальных майнеров в сети.
«Вы строите гигантскую стену»,- говорит Питер Кирби, президент Factom. «И каждый раз, когда вам нужно о чём-то договориться, вы кладёте наверх тысячу кирпичей. Договариваетесь о чём-либо ещё, и кладёте ещё одну тысячу кирпичей сверху. Это делает очень, очень сложным делом для кого угодно убрать один кирпичик снизу стены».
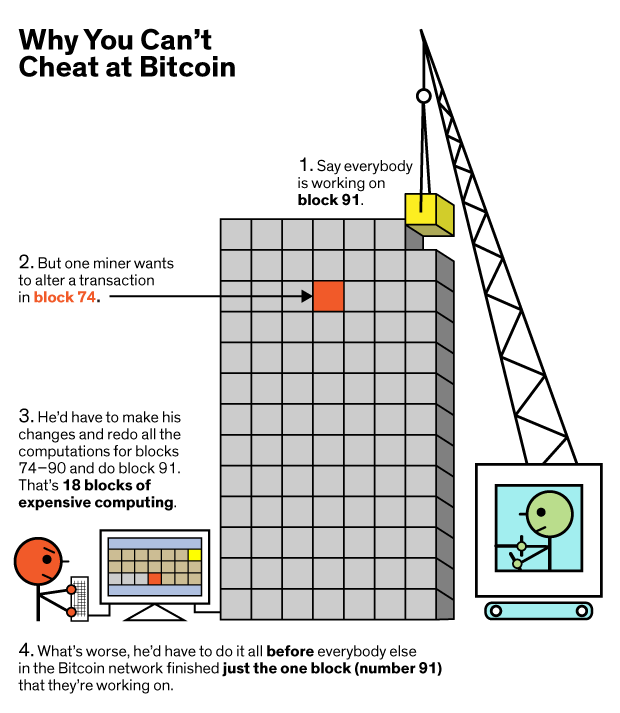
Не верите? Давайте проведём атаку на систему.
Допустим, в цепочке блоков биткоин имеется запись, которую я хочу изменить, и она содержится в сотом блоке цепи. Тем временем сообщество майнеров уже решает блок № 110. Чтобы мои изменения были приняты сетью, мне нужно предоставить мою альтернативную версию всей цепочки. Мне надо откатиться до блока 100, изменить запись, и выполнить необходимые расчёты. Поскольку все последующие хэши основаны на изменённых мною данных, мне придётся повторить работу над каждым из последующих блоков, вплоть до 110.
И мне нужно сделать это до того, как майнеры целого мира закончат 110-й блок. Остальные станут работать над моей альтернативной цепью, только если я выдам им цепь, длиннее, чем та, над которой они уже работают. Но я – просто майнер-одиночка с малой долей компьютерных мощностей по сравнению с целой сетью, поэтому я их никогда не догоню. Более того, чтобы провернуть такой трюк, мне необходимо контролировать более половины всех вычислительных мощностей, которые используются в сети биткоин в любой момент времени.
А это большая сеть. Соревнуясь друг с другом, майнеры инвестируют в компьютеры со специализированными чипами, ASIC, которые разработаны для подсчёта хэшей. Скорость обработки компьютеров в сети удвоилась с августа 2014 по март 2015, и цифры всё растут. Некоторые из этих вычислительных центров – это гиганты, потребляющие по 500 киловатт и требующие специально подобранного жидкостного охлаждения.
Значит, цепочка блоков Накамото становится тем безопаснее, чем больше людей участвуют в сети. Но зачем им это нужно? В случае биткоин – потому, что им за это платят. Каждый раз при решении блока создаётся новая транзакция, по которой немножко новых биткоинов присваиваются первому майнеру, завершившему работу.
В старых моделях безопасности вы пытались отгородиться от всех жадных и нечестных людей. Биткоин приглашает всех, рассчитывая на то, что они будут работать в собственных интересах, и использует их жадность для обеспечения безопасности сети.
«Это и есть главный вклад,- говорит Иттай Ийял [Ittay Eyal], специалист по информатике из Корнелла, изучающий биткоин и другие децентрализованные сети. Биткоин устроен так, что атакующему выгоднее работать вместе с системой, а не атаковать её. Система побуждений поощряет вносить вклад при помощи своих ресурсов на благо системы».
При использовании цепи блоков для хранения записи о некоей сумме мы получаем сеть биткоин. Когда Накамото запустил биткоин в 2009 году, цепь блоков была всего лишь последовательностью транзакций. Но люди быстро поняли, что транзакции можно приспособить в качестве транспорта для включения в цепь нефинансовых данных.
В прошлом году после бурных обсуждений разработчики протокола добавили возможность присоединять 40 байт метаданных к каждой транзакции.
Теперь цепочка забита всякими нефинансовыми сообщениями. Валентинками, молитвами, хвалебными речами, выдержками из викиликс, хэшами текстов книг и конечно изначальной научной работой, описывающей технологию биткоин. Всё это живёт в цепочке блоков, будучи включённым в транзакции.
Когда метаданные включаются в цепочку, они получают все преимущества использования p2p сети. Эти данные доступны любому на планете, имеющему компьютер и подключение к интернету. Чтобы уничтожить их, вам понадобилось бы достучаться до каждого компьютера в сети. Их невозможно изменить, и значит, невозможно применять к ним цензуру. У них есть как время создания, так и криптографическое доказательство авторства.
Так что же можно делать с цепочкой блоков? Простейший вариант – несложная система хранения, имеющая уникальные преимущества. Все, кому интересна прозрачность и доступность, видят в цепочке способ организации и хранения важных записей и возможность включения людей в законодательный процесс.
Поскольку у каждой записи есть временная метка, её можно использовать, как децентрализованный нотариат. Представьте, что вы сфотографировали вмятину на арендованном авто и загрузили в цепочку блоков. Пользуясь свойствами цепочки позже вы сможете доказать, что вмятина была на машине ещё до того, как вы уехали с парковки.
Поскольку транзакции биткоин защищены криптографически, сеть также может заменить стандартный подход «логин+пароль». В такой системе адрес биткоин может быть именем пользователя, а приватный ключ – паролем. Каждый может попросить вас подтвердить свою личность, решив при помощи вашего ключа ту же задачку, которую вы решали бы, создавая транзакцию.
Цепочка также решает проблему цензуры. Если один раз вставить метаданные в цепь, их уже невозможно убрать оттуда. Разработчики использовали эту возможность для создания нецензурируемой версии Twitter под названием Twister и децентрализованной системы доменных имён (Namecoin).
«Всё, чем вы владеем и что делаем, управляется пачкой записей»,- говорит Кирби. «Банк – это просто куча записей. Страховая компания – куча записей. Экономика – это куча записей. Если вы можете принять концепцию мирового гроссбуха и сказать: „Теперь мы можем организовать таким образом все записи в мире“, то это очень здорово».
Пока что это все примеры того, как можно использовать цепочку блоков для изменения методов хранения данных в интернете. Но хранение – это вершина айсберга. Биткоин – это не просто гроссбух с транзакциями. При нём есть армия майнеров, работающих как одна распределённая виртуальная машина.
Сегодня их роль проста. После сбора пачки запросов майнер прогоняет их через программу проверки. Она подтверждает, что вы – тот, кем вы представляетесь, и что у вас достаточно биткоинов для проведения транзакции. Затем вашу транзакцию принимают или отбрасывают.
А что если попросить майнеров сделать что-то ещё? К примеру, «не одобряйте транзакцию, пока я жив». Или «при одобрении транзакции подправьте количество отправляемых монет с учётом цены акций Tesla Motors».
Первый пример – это зачаток автоматического распределения средств по завещанию без необходимости в адвокате. Второй – децентрализованная биржа.
Примеры упрощены и создают новые проблемы, но они просто иллюстрируют мнение – совершаемые майнерами расчёты могут превратиться во что-то более экзотическое. Это основа того, что называется «умными контрактами», в которых майнеры обеспечивают выполнение финансовых обязательств. Можно даже представить себе автономные корпорации, связывающие финансовые транзакции на умные устройства с контрактами, заключёнными через цепочку блоков.
Сейчас у биткоин есть ограничения на подобные контракты. Минималистичный язык программирования ограничивает виды операций, которые могут проводить майнеры. Но разработчики постоянно обсуждают новые дополнения к протоколу.
Необходимо будет добавить гибкости в протокол, если биткоин захочет выйти за рамки статического гроссбуха. В 2012 году разработчики, предвидя это, добавили транзакции с множественными подписями. Они позволяют пользователям разделять владение адресами на несколько человек, присваивая им несколько приватных ключей. С тех пор многие компании предлагают эскроу-услуги на основе таких транзакций.
Изменения в протоколе требуют времени. Чтобы убедиться, что все участники сети играют по правилам, нужно так вносить изменения, чтобы они удовлетворили всех заинтересованных лиц. Этот процесс может быть утомительным. Некоторые считают, что он ограничивает эволюцию биткоина. «Сейчас существует уже пять разных сторон, участвующих в нахождении консенсуса: разработчики, майнеры, продавцы, пользователи и провайдеры услуг. Обычно требуется согласие всех пяти сторон, чтобы внести изменения в протокол,- говорит Андре Антонополус [Andreas Antonopoulos], автор инструкции „Осваиваем биткоин“. – Мы приближаемся к окончанию эры, в которой были возможны радикальные изменения».
Недавно программисты, участвующие в разработке, предложили возможное решение проблемы. Адам Бэк, криптограф, разработавший центральный для безопасности биткоина функционал, уже давно пропагандирует создание параллельных цепочек блоков, или сторонних цепочек (sidechains). Они должны работать как источник инноваций в экосистеме биткоин. Можно было бы заморозить ваши монетки в основной цепочке блоков, чтобы их нельзя было потратить, и перевести их в параллельную цепочку, сообщающуюся с основной. Она принимает обмены, но работает по своим правилам. И процесс должен быть обратимым. Используя сторонние цепочки, разработчики могли бы свободно конструировать экзотические платформы. Владельцы биткоин могли бы совершать оплату через эти экспериментальные цепочки, не покидая совсем систему биткоинов.
Недавно компания Blockstream, основанная Бэком вместе с десятком других уважаемых в сообществе людей, выпустила реализацию сторонних цепочек с открытым кодом под названием Sidechain Elements.
Тем временем Ethereum не ждёт, пока цепочка блоков биткоин подтянется до его амбиций. Это проект, работающий с новой цепочкой, который хочет превратить сеть майнеров в рабочий распределённый компьютер. Вместо раздачи майнерам нескольких новых команд, которые нужно выполнить во время обработки транзакции, Ethereum позволяет им запускать любые программы. Это значит, что майнеры могут запускать софт, вообще не имеющий отношения к транзакциям. Теоретически платформу можно будет использовать для взаимодействия с любым приложением, заменяя набор интернет-серверов одной большой распределённой виртуальной машиной. Конечная цель выглядит вовсе фантастичной. «Мы строим новый тип интернета»,- утверждает Любин.
«В проекте Ethereum, поскольку каждый узел является полноценной виртуальной вычислительной машиной. разработчик может загрузить транзакцию с компьютерным кодом, и добавить её в сеть,- говорит он. – Система распознает его и установит код на каждом узле сети. Через несколько секунд ваше приложение будет работать по всему миру».
Взаимодействие с приложениями заключается в отправке «эфиров» (ethers, аналог биткоинов) в сеть и запросе доступа к софту в цепочке блоков.
Финансирование проекта было исключительно успешным. Зарегистрированная в Швейцарии некоммерческая организация Ethereum Foundation решила получить финансирование, продавая эфиры всем желающим. В отличие от биткоина, Ethereum Network была разработана так, чтобы создать набор монет-эфиров до начала работы сети. Прошлым летом в течение 42 дней фонд продавал часть своих резервов в обмен на биткоины. Продажа принесла 31529 бикоинов (на тот момент аналог $18 миллионов, но сейчас это уже раза в два меньше).
За последние месяцы разработчики показывали предварительные версии своего софта на различных встречах. В марте в Нью-Йорке Коннор Кинан показал приложение, выполняющее все функции веб-форума типа Reddit. Код программы записан в софтовый объект под названием «контракт» в тестовой версии цепочки Ethereum. Для использования программы необходимо создать и распространить по сети транзакцию (потратив небольшое количество эфиров, отправив их на адрес контракта). Майнеры запустят локальные копии этой программы на своих компьютерах, позволяя вам добавлять посты и комментарии, и т.п. Другой докладчик показал рудиментарную видеоигру.
Можно представить программы, принимающие транзакции для показа фильмов, обеспечения сложных финансовых контрактов или организации децентрализованной корпорации.
Возьмём аренду автомобилей. Вместо того чтобы идти к окошку и общаться с человеком, который проведёт вашу кредитку и выдаст вам ключи, вы отправляете транзакцию через Ethereum, устанавливающую контракт между вами и фирмой-арендатором. Эта оплата будет и тем кодом, который активирует смарт-карту (или мобильное приложение, или любой другой вид ключа), чтобы вы могли завести машину. Другие программы в цепочке блоков отследят количество пройденных километров и подсчитают стоимость аренды, а прибыль будет автоматически отправлена владельцам компании. Приверженцы биткоинов считают, что эта модель не только не нужна, но и опасна. «Я с недоверием отношусь к сложным идеям – распределённым автономным корпорациям, работающим независимо и каким-то чудесным образом обеспечивающим свою безопасность»,- говорит Гэвин Андресен, один из основных разработчиков биткоин-протокола. «Может быть, когда-нибудь, когда у нас будут робомобили и роботы-инспекторы, мы сможем позволить себе компанию, управляемую кодом без людей. Может быть, тогда нам и понадобятся сложные контракты в цепочке блоков. Но я считаю, что до этого ещё очень далеко».
Если мы и придём туда, считает Любин, то не через биткоин. «Это очень узкий протокол. Он делает только одну вещь, и делает её хорошо,- говорит он. – Наверно, можно было бы построить всё, что умеет Ethereum, через биткоин. И это заняло бы у вас в 10-100 раз больше времени. В Ethereum всё происходит на уровне приложений. Он превращает всё на уровне приложений в софт, написание которого доступно миллионам людей – в отличие от сложной возни с криптографическими примитивами».
Удивительно, что всего лишь через шесть лет после создания биткоин появились те, кто уже считает систему слишком тесной. Разработчики могут спорить по поводу того, как выглядит будущее и где появится следующее поколение биткоин-приложений, но они сходятся в одном: будущее не будет централизованным. Хотя бы в этом вопросе приверженцами биткоина был достигнут счастливый консенсус.
This entry passed through the Full-Text RSS service - if this is your content and you're reading it on someone else's site, please read the FAQ at http://ift.tt/jcXqJW.