В разработке дизайна для
email-рассылок многие специалисты недостаточно много внимания уделяют типографике. Тем не менее, даже несмотря на некоторую ограниченность электронной почты как среды для дизайнерских решений, работа с типографикой может сделать письма значительно лучше.
Сегодня мы представляем вашему вниманию адаптированный перевод исследования Анны Иман (Anna Yeaman), соосновательницы и директора американского агентства, которое было изначально опубликовано на страницах авторитетного ресурса SmashingMagazine.
В прошлом году я прочитала пост Яна Константина (Jan Constantin) «Тенденции и современные методы типографского дизайна» и тут же решила провести похожую работу, но применительно к почтовой рассылке. В то время я изучала адаптивную веб-типографику. Я выделила группу сайтов, которые мне понравились, и попыталась разобраться, в чем секрет их типографики, чтобы потом применить новые знания к разработке дизайна email-рассылки.
После того, как я познакомилась с работой Константина, мне захотелось понять, как другие дизайнеры email-рассылок использовали адаптивную типографику. В итоге я собрала 50 примеров почтовой рассылки из разных сфер, в которых, на мой взгляд, подобрана качественная типографика, и решила проверить, есть ли у них что-то общее. Исходные данные и результаты этой работы вы можете посмотреть в Google-таблице.
Методология
Учитывая тот
факт, что около 50% всех электронных писем открывается с мобильных устройств, все письма, выбранные для исследования, были адаптивными, состояли из одной колонки основного текста и заголовка. Я собрала статистику по трем типам устройств в зависимости от ширины экрана: большим (ПК), средним (450 пикселей) и маленьким (320 пикселей).
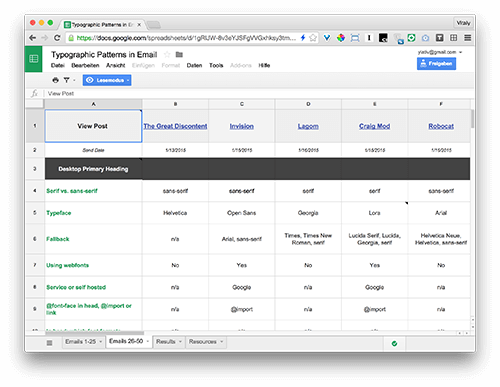
Google-таблица с полным обзором по каждому письму
Я знала, что выборка из 50 писем вряд ли окажется статистически значимой. Я лишь хотела выявить ряд общих тенденций. Средним значением в статье я обозначаю математическое ожидание. Самым популярным значением – то, которое встречается чаще всего. Также в нескольких случаях я использую понятие медианного значения. Все письма, исследованные в работе, рассылались в период с ноября 2014 года по январь 2015 года. В работе я пользовалась такими инструментами, как WhatFont, Charcounter и WebPagetest.
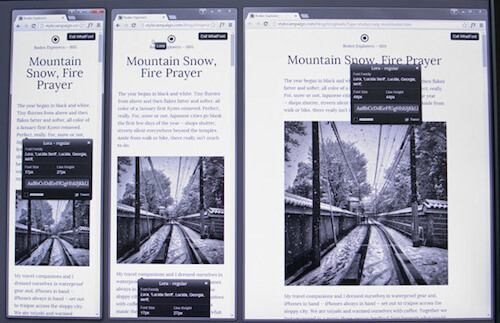
Как письмо отображается на трех типах устройств в приложении WhatFont
Что мне было интересно
Я отвечала почти на те же вопросы, что и Константин, за рядом исключений. В общей сложности было сделано около 90 выводов, и в этом посте рассмотрены лишь основные:
- Насколько популярны гарнитуры с засечками и без засечек в заголовках и в теле письма?
- Какие гарнитуры используются чаще всего?
- Какой размер шрифта чаще всего встречается в теле письма, и меняется ли эта частота при переходе с ПК на мобильное устройство?
- Каково среднее число символов в строке для каждого типа экрана?
- Какова самая популярная ширина строки в письме на ПК?
- Каково среднее отношение высоты строки в теле письма к размеру шрифта?
- Каково среднее отношение между высотой и длиной строки в теле письма?
- Используется ли в заголовке и в теле письма один и тот же цвет?
- Какие цвета чаще всего используют для фона?
- Как выравнивается текст в заголовке и в теле письма в зависимости от типа экрана?
- Какой размер шрифта чаще используется в заголовках?
- Прикрепляют ли ссылки к заголовкам?
- Каковы размер и цвет текста подзаголовка письма и отображается ли этот текст на мобильных устройствах?
- Как долго в среднем загружается письмо?
- Как много весят веб-шрифты по сравнению с картинками?
Шрифты с засечками и без засечек
- 74% шрифтов, которые использовались в заголовках, были без засечек;
- 64% шрифтов, которые использовались в теле письма, были без засечек;
- Самые популярные шрифты без засечек в заголовках – Helvetica (16%) и Arial (14%);
- Самые популярные шрифты с засечками в заголовках – Georgia (14%) и Merriweather (4%);
- Самые популярные шрифты без засечек в теле письма – Helvetica или Neue Helvetica (20%), Arial (10%);
- Самые популярные шрифты с засечками в теле письма – Georgia (24%), Merriweather и Times (по 4% каждый);
- Шрифты с засечками на 10% чаще использовались в теле письма, чем в заголовках;
- В теле письма встречались всего 5 различных шрифтов с засечками и 15 различных шрифтов без засечек;
- В заголовках встречались 24 разных типа шрифтов, из которых 16 встречались по одному разу;
- В теле письма встречались 20 разных типов шрифтов, из которых 11 встречались по одному разу;
- Times New Roman оказался непопулярен: его не использовали ни в одном из заголовков.
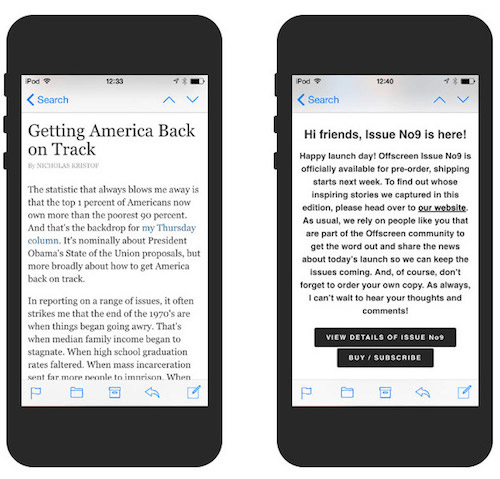
Helvetica стала самым популярным шрифтом в заголовках и использовалась в 16% случаев, как, например, в рассылках
Offscreen и
TGD. Georgia чаще всего использовалась в теле письма (24%), как, например, в рассылках
Mr Porter и
New York Times. Набирают популярность две гарнитуры из набора Google Fonts – Merriweather и Open Sans, которые можно увидеть в рассылке
iOS Dev Weekly и
InVision.
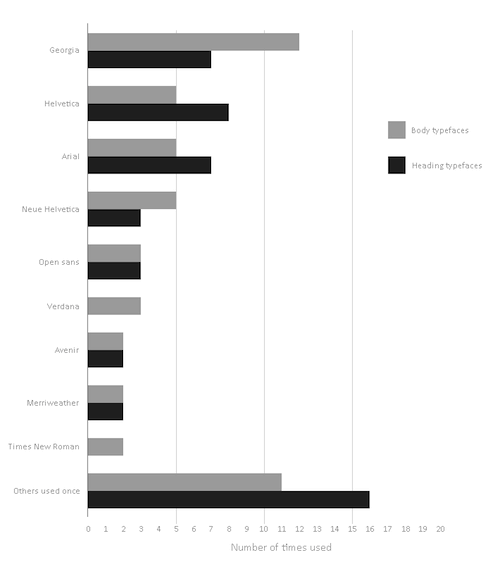
Самые популярные гарнитуры в заголовках и в теле письма
Константин отмечает, что шрифты с засечками стали использоваться намного чаще в основных текстах веб-сайтов (61,5%). Наше исследование показало, что для писем этот показатель составляет 36%. Возможно, в своей работе он больше изучал новостные сайты, в которых чаще встречаются шрифты с засечками. Кроме того, в рассылке редко встречается много текста, так как основной контент обычно располагается на посадочной странице. Интересным примером является сайт Крейга Мода (Craig Mod), который использует шрифт с засечками Lora из Google Fonts как в заголовках, так и в теле письма. Чаще всего шрифты с засечками и без засечек используются вместе: примером может служить классическая комбинация Helvetica-Georgia в рассылке MailChimp.
В 36% случаев в теле письма используются шрифты с засечками, в 64% – шрифты без засечек
Для выбора гарнитуры рекомендую прочитать пособие «Комбинируем гарнитуры» и статью «Классные комбинации шрифтов». Помимо этого, Пол Эйри (Paul Airy) пишет о том, как комбинировать шрифты в email-рассылке. И если вы думали, что в письмах не встречаются веб-шрифты, то вы ошибаетесь.
Тело письма
На сайте Butterick’s Practical Topography
пишут: «В любом проекте первым делом надо красиво оформить основной текст и только потом беспокоиться об остальном». Во многих статьях по типографике также говорят, что начинать нужно всегда с оформления основного текста. Самое главное – соблюдать пропорции между размером шрифта, форматом или длиной строки и высотой строки, учитывая при этом еще и ширину экрана устройства.
Размер шрифта
- Самый популярный (44%) размер шрифта на ПК – 16 пикселей;
- Медианный размер шрифта на ПК – также 16 пикселей (среднее значение – 15,7 пикселей);
- В теле письма, открывающегося с ПК, размер шрифта менялся от 13 до 20 пикселей;
- Самый популярный (38%) размер шрифта на мобильных устройствах – 16 пикселей;
- Медианный размер шрифта на мобильных устройствах – также 16 пикселей (среднее значение – 15,58 пикселей);
- В теле письма, открывающегося с мобильного устройства, размер шрифта менялся от 13 до 20 пикселей;
- В 72% случаев при переходе с ПК на мобильное устройство размер шрифта не менялся;
- В оставшихся 28% случаев при переходе с ПК на мобильное устройство текст чаще уменьшался (64%), чем увеличивался (36%).
Ключевым фактором в выборе размера шрифта является расстояние [от читателя] до экрана устройства. Экран ПК располагается на расстоянии вытянутой руки, поэтому 20-пиксельный текст письма от Robocat, набранный шрифтом Helvetica (на фото справа), читать проще, чем рассылку Patagonia с 14-пиксельным Muli (на фото слева). iA пишет, что в своем приложении Writer при чтении на iPad компания использует более крупный шрифт, чем на iPhone, потому что iPad мы держим чуть дальше от себя.
На расстоянии текст размером 20 пикселей (справа) воспринимается легче, чем текст размером в 14 пикселей (слева)
Формат строки
Еще один фактор, о котором нельзя забывать при учете пропорций шрифта – это
формат строки, то есть ширина тела письма. Формат строки измеряется либо в пикселях, либо в количестве символов в строке – разработчики электронных писем обычно не работают с кеглем. Роберт Брингхерст (Robert Bringhurst)
советует использовать в строке текста письма с одной колонкой, адаптированного под ПК, от 45 до 75 символов, идеальный вариант – 66 символов (с учетом пробелов).
- 600 пикселей – самая популярная ширина тела письма для ПК (диапазон – от 480 до 760 пикселей, среднее значение – 623 пикселя);
- 540 пикселей – средняя ширина колонки на ПК;
- В строке текста на ПК в среднем располагается 78,5 символа;
- В строке текста шириной 450 пикселей в среднем располагается 53,86 символа;
- В строке текста шириной 320 пикселей в среднем располагается 39,02 символа;
- Формат строки на мобильных устройствах варьируется от 22 до 57 символов;
- В 76% случаев этот диапазон сужается до 36-46 символов.
Я провела небольшой эксперимент со шрифтом Georgia размером 16 пикселей при среднем формате строки в 540 пикселей. При таких параметрах число символов в строке будет чуть больше 70, и это не так плохо, если учесть, что 75 – максимум. Но в идеале лучше сократить число символов до 66, при этом ширина строки оказывается в районе 480 пикселей.

Роберт Брингхерст советует располагать в одной строке от 45 до 75 символов, идеальный вариант – 66 символов. Источник: Practical Typography
По подсчетам Константина, на строке веб-страницы в среднем располагается 83,9 символа. В нашем исследовании в строке тела письма содержится в среднем 78,5 символа. При просмотре писем на мобильном устройстве среднее число символов сокращается до 39. Typecast рекомендует придерживаться диапазона 35-40 символов при просмотре писем на обычном смартфоне. По результатам нашего исследования, в этот диапазон попало 48% писем.
Самым популярным (53%) форматом строки в шаблонах писем, адаптированных для ПК, был вариант шириной в 600 пикселей. В целом ширина экрана изменялась от 480 до 760 пикселей. Если вы хотите сделать колонку более широкой, просто увеличивайте размер шрифта до тех пор, пока не достигнете оптимального числа символов. Трент Уолтон (Trent Walton) предлагает оригинальное решение: нужно поместить символ «*» на две отметки – в 45 и 75 символов. Таким образом, если в какой-то момент обе звездочки оказываются в одной строке, это значит, что шрифт нужно увеличить.
Высота строки
Ниже представлены основные выводы, касающиеся высоты строки.
- При размере шрифта в 16 пикселей самой популярной высотой строки была высота в 24 пикселя;
- Среднее отношение высоты строки к «высоте» (общему объему) текста составило 1,51 (у Константина – 1,46);
- При 450-пиксельной ширине строки отношение высоты строки к высоте текста снижается до 1,49;
- При 320-пиксельной ширине строки отношение высоты строки и к высоте текста снижается до 1,45;
- 22% компаний, попавших в исследование, уменьшают высоту строки для писем, адаптированных под мобильные устройства;
- 52% устанавливают высоту строки в пикселях;
- 24% устанавливают высоту строки в процентах;
- Отношение длины строки к ее высоте в среднем составляло 23,1 (у Константина – 24,9);
- Отношение величины отступа между абзацами к высоте строки в среднем составляло 1,38 (у Константина – 1,39).
Стандартное правило: высота строки должна быть в 1,5 раза больше размера шрифта. То есть если размер шрифта – 16 пикселей, значит, высота строки составит 24 пикселя. Проведенное исследование подтверждает это правило: отношение высоты строки к размеру шрифта составило 1,51. Чем больше длина строки, тем большей можно сделать ее высоту.
Тим Браун (Tim Brown) называет такое изменение высоты «плавным» или «текучим». Джейсон Санта Мария (Jason Santa Maria ) поясняет: «Когда ваш взгляд доходит до конца строки, вам нужно увидеть промежуток между строками и понять, где находится следующая строка, чтобы не потеряться… Если строки становятся короче, значит, их можно разместить немного плотнее». Мы также отметили снижение этого отношения при переходе на мобильное устройство – оно упало с 1,51 до 1,45.
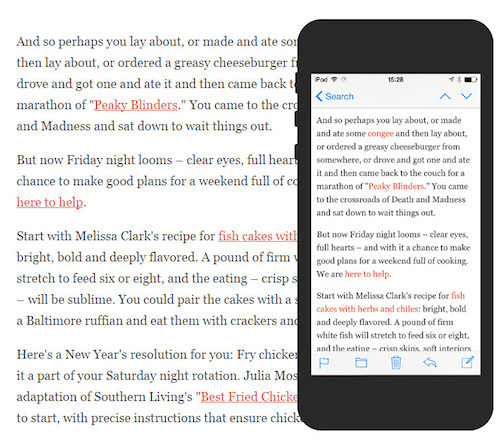
Высота строки в рассылке NYT Cooking снижается с 30 пикселей на ПК до 25 пикселей на смартфоне (отношение высоты строки к размеру шрифта снижается с 1,6 до 1,5)
52% дизайнеров email-рассылок устанавливает высоту строк в пикселях. Некоторые компании, например, Semplice, меняют высоту строки для разных элементов письма. 24% выставляют высоту в процентах. К примеру, Lagom устанавливает высоту 150%. Оливер Райхенштайн (Oliver Reichenstein) считает, что 140% – «неплохой ориентир», хотя многое зависит от выбранной гарнитуры. Пол Эйри советует выставлять высоту в процентах, потому что в пикселях сложнее подобрать нужное соотношение. Тем не менее, разработчики, скорее всего, привыкли к пикселям, так как они поддерживаются многими почтовыми клиентами.
Цвет
- #000000 (черный) был самым популярным цветом текста (20%), следом за ним идет #333333 (сумеречный серый) (16%);
- В письмах использовалось 28 различных оттенков серого, большинство из которых – темно-серые;
- 56% авторов рассылок использовали одинаковый цвет текста как в заголовке, так и в теле письма;
- 26% в теле письма использовали более светлый оттенок серого, чем в заголовке, 4% – более темный, а 14% брали разные цвета;
- 72% в качестве фона использовали #FFFFFF (белый);
- 48% не вставляли ссылки в тело письма, 20% выделяли ссылки другим цветом, 18% выделяли цветом и подчеркивали, 10% только подчеркивали, и 4% использовали другие варианты;
- #000000 был самым популярным цветом для основного заголовка (24%), следом за ним – #333333 (16%);
- 40% подзаголовков отличались цветом от основного заголовка: например, выделялись более светлым оттенком серого.

Несколько цветовых комбинаций для заголовка (вверху) и тела письма (внизу)
Оливер Райхенштайн пишет: «На высококонтрастном экране предпочтительнее выбирать либо темно-серый цвет для основного текста, либо светло-серый – для фона вместо оттенков черного и белого».

#FFFFFF стал самым популярным (72%) цветом для фона письма
При использовании более насыщенных шрифтов Джейсон Санта Мария советует либо увеличить высоту строки, либо выбрать более светлый тон, чтобы не нагружать остальной контент. Разработчики иногда регулируют цвет текста на разных устройствах в зависимости от того, как отображаются на них шрифты разных размеров. В Photoshop невозможно четко определить, подходит шрифт для рассылки или нет: приходится изучать его поведение в браузере с помощью самодельных прототипов, Typecast или Typetester.
Выравнивание
- 54% основных заголовков на ПК выровнены по центру, 46% – по левому краю;
- 54% основных заголовков на мобильных устройствах выровнены по левому краю, 46% – по центру;
- 74% создателей рассылок выравнивают основной текст на ПК по левому краю, остальные 26% – по центру;
- 76% выравнивают основной текст на мобильном устройстве по левому краю, остальные 24% – по центру.
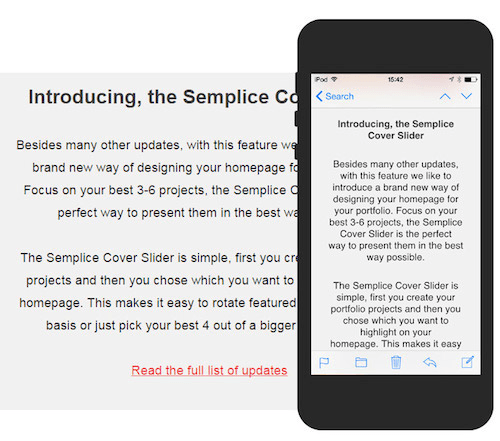
Если основной текст выровнен по центру, то читать бывает сложнее, так как каждый раз приходится искать начало следующей строки
Пользователи, на которых мы тестировали рассылки, постоянно говорили, что текст, выровненный по центру, читать сложнее. «Возможно, блоки, в которых много текста, читать чуть сложнее. Думаю, это потому, что текст выровнен по центру», – написал один участник эксперимента в UserTesting. То же можно сказать и о более узких экранах мобильных устройств. Подписи, короткие предложения и заголовки, выровненные по центру, воспринимаются нормально, но когда дело доходит до абзацев, текст приходится выравнивать по левому краю. Как упоминается в «Оде центрированному тексту», целые абзацы никогда нельзя выравнивать по центру.
Средний размер шрифта в заголовках
- 30 пикселей – самый популярный (18%) размер в заголовках на ПК (30 пикселей – также и медианный размер, а средний размер – 31,6 пикселя);
- Размеры шрифта в заголовках на ПК делились на две группы: от 24 до 26 пикселей и от 28 до 36 пикселей;
- Шрифт в заголовках в среднем был ровно в два раза крупнее шрифта в теле письма (31,6 и 15,7 пикселя соответственно);
- Шрифт в заголовках на ПК в среднем был в 1,2 раза больше высоты строки (это соотношение варьировалось от 0,65 до 1,8);
- Ссылки не крепились к 62% основных заголовков на ПК;
- 68% создателей рассылок не меняли размер шрифта в заголовке при переходе с ПК на 450-пиксельный формат ширины письма; 87,5% из тех, кто менял размер шрифта, уменьшали его;
- 64% выбирали одинаковые размеры шрифта для заголовка на ПК и на мобильных устройствах (один масштаб);
- На мобильных устройствах для основного заголовка чаще всего выбирали размер в 30 и 32 пикселя (оба по 12%);
- Средний размер шрифта в основном заголовке на мобильном устройстве (320 пикселей) составил 28,48 пикселя (медианный размер шрифта был 26,5 пикселя)
- Отношение размера шрифта в заголовке к высоте строки в среднем составляло 1,17 для мобильных устройств;
- Только 14% использовали в заголовке одни прописные буквы (как правило, это были магазины одежды);
- 72% использовали подзаголовки;
- Средний размер шрифта подзаголовков – 27,9 пикселя (для десктопа).
Многие разработчики писем не пользуются тегами h2, h3 и т.д., поэтому я фиксировала первый и второй по величине шрифты в заголовках с помощью приложения WhatFont. Самый популярный размер шрифта в основных заголовках на ПК – 30 пикселей, тогда как у Константина этот показатель составляет 38 пикселей по Сети в целом. Возможно, более мелкий шрифт выбирается для удобства чтения как на ПК, так и на мобильных устройствах.
64% использовали одинаковый масштаб в заголовках на всех типах устройств. Если говорить об оставшихся 36%, то 87,5% из них уменьшали масштаб на мобильных устройствах. К примеру, в рассылке от Mr Porter размер шрифта на мобильном устройстве уменьшен с 30 до 25 пикселей – небольшое изменение, которое делает стиль более элегантным, в отличие от громоздких заголовков на ПК.
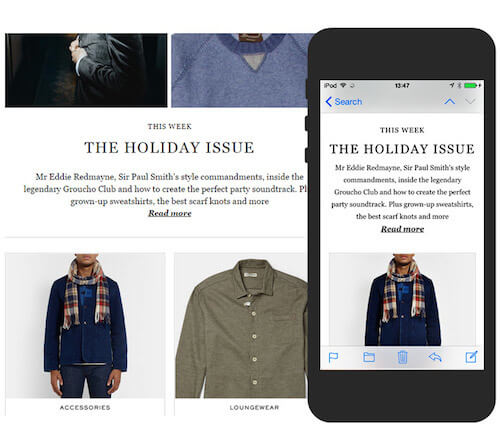
Размер шрифта заголовка в рассылке Mr Porter снижается с 30 пикселей на ПК до 25 пикселей на мобильном устройстве
О точных размерах заголовков нет единого мнения, хотя в десктопной версии шрифт заголовка был в среднем в два раза больше шрифта в теле письма. Для сравнения, на Typecast пишут, что их значения h1 в три раза больше шрифта основного текста, хотя в интернете можно найти и более крупные заголовки. Если хотите поэкспериментировать с разными соотношениями, воспользуйтесь сервисом Modular Scale. Кроме того, есть стандартная типографская шкала:

Шкала из «Основ стиля в типографике» Роберта Брингхерста. Изображение: Retinart
В качестве альтернативы использования размера шрифта для визуального выделения, Марко Дугоньич (Marko Dugonjić ) предлагает менять стиль текста: например, курсив, все прописные или капитель [англ. small caps]. Посмотрите его демо-вариант (раздел «Выделение со сменой стиля»). Этот подход будет особенно полезен на мобильных устройствах, где меньше пространства для крупных заголовков. Еще один вариант – переключиться на узкий шрифт. Заголовки являются творческой площадкой для дизайнеров. Здесь у них появляется больше вариантов для размеров шрифтов и выравнивания, а также больше возможностей использовать веб-шрифты, в отличие от текста в теле письма.
Текст под заголовком
Записи под заголовком находятся вверху письма. Это первый текст, который пользователи обычно видят на своих смартфонах, вместе с именем отправителя и темой. В своем исследовании я разграничиваю понятия инструктивной надписи, например, «Смотреть онлайн», и отрывка текста, который более информативен и зачастую дополняет тему письма. Litmus подробно рассматривает этот вопрос в своем
обзоре и приводит в нем таблицу приложений, которые отображают текст под заголовком.
- 66% создателей рассылок используют текст под заголовком на ПК;
- 36% включают в него только инструкции, 33% – инструкции и отрывок письма, 30% – только отрывок;
- Самый популярный размер текста под заголовком на ПК – 11 пикселей (33%), далее 12 пикселей (18%) и затем 10 пикселей (12%) (среднее значение – 12,3 пикселя);
- Размеры шрифта текста под заголовком варьируются от 9 до 18 пикселей;
- Отношение размера текста под заголовком к размеру основного текста в среднем составляло 0,78;
- Отношение размера текста под заголовком к высоте строки на ПК в среднем составляло 1,11;
- 76% использовали в тексте под заголовком гарнитуры без засечек;
- Самым популярным шрифтом без засечек был Arial, с засечками – Georgia;
- В текстах под заголовком использовались 22 разных цвета, самый популярный – #000000, затем #999999;
- 82% поддерживали текст под заголовком на мобильных устройствах, 18% его скрывали;
- Самый популярный размер текста под заголовком на мобильных устройствах – 11 пикселей (40%), далее 16 пикселей (22%) и затем 14 пикселей (18%) (средний размер шрифта – 12,9 пикселя);
- Размеры шрифтов текста под заголовком на мобильных устройствах варьировались от 8 до 16 пикселей;
- 71% сохраняли размер при переходе на мобильные устройства, 22% увеличивали шрифт, 7% уменьшали;
- Отношение размера текста под заголовком к размеру основного текста на мобильном устройстве в среднем составляло 0,85.
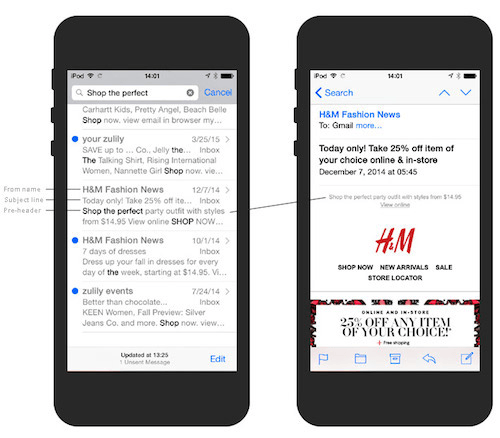
Текст под заголовком отображается вместе с именем отправителя и темой письма
Производительность
- Время, за которое отображался первый элемент письма, в среднем составляло 0,94 секунды;
- Время полной загрузки письма в среднем составляло 2,64 секунды;
- Общее число HTTP-запросов в среднем составляло 24;
- Число запросов на изображения в среднем составляло 13,7, то есть 57% от общего числа запросов;
- Полностью загруженное письмо в среднем весило 711 КБ;
- Изображения в письме весили в среднем 568 КБ;
- На изображения приходилось 79,8% объема всего письма;
- Размер изображений изменялся от 9 КБ до 4,4 МБ, из них 50% весили 200 КБ и более;
- Веб-шрифты в среднем занимали 69,7 КБ (9,5% объема всего письма);
- 30% использовали веб-шрифты (самым популярным был Open Sans, затем Merriweather).
Первоначально я включила в свое исследование производительность, так как часто слышала о том, как веб-шрифты ее снижают. Если взглянуть на
список 20 лучших шрифтов Google Fonts, можно увидеть, что их средний объем составляет 28 КБ (формат WOFF) на один шрифт. Если учесть, что большинство участников исследования использовало по три шрифта, то сумма сходится (средний объем загруженного шрифта составлял 69,7 КБ). Хотя веб-шрифты иногда могут стать причиной для беспокойства, они занимают всего 9,8% общего объема письма. Сравните их с изображениями, которые занимают 79,8% от всего письма.
Гай Поджарный (Guy Podjarny) также отмечает, что изображения несут основную нагрузку в письме. Полезный инструмент, о котором вы могли не знать – Litmus. Он показывает число картинок, размер и время загрузки во время предварительного просмотра.

<Изображения в среднем составляют 79,8% от общего объема письма (средний объем загруженного изображения составляет 568 КБ)

Согласно этой ленте, письмо H&M загружается за 4,095 секунды, т.е. в этот момент что-то только начинает появляться на экране
Заключение
Изначально я хотела узнать, как сайты вроде iA, Fray, Medium и Pelican Books создают такие «эталонные» примеры подбора типографики, и попытаться использовать их идеи как основу для разработки гайдлайнов по дизайну email-рассылок. К примеру, может ли существовать четкая связь между размером шрифта и величиной отступа на мобильных устройствах?
В процессе исследования и после того, как я по-другому взглянула на их сайты, я поняла, что ни один из приведенных наборов соотношений не будет универсальным. Как поясняет Тим Браун, хорошую типографику нельзя просто скопировать, потому что она зависит от используемой гарнитуры.

Несмотря на то, что размер шрифта для веб-страницы следует выбирать лишь из определенного диапазона, разработчики и здесь находят пространство для творчества
Тем не менее, проведенное исследование дает некоторую основу для разработки дизайна электронных писем: например, если за размер основного текста берется 16 пикселей при высоте строки в 24 пикселя, вам остается лишь выбрать подходящую гарнитуру и отрегулировать длину строки. Особенно полезными оказались найденные пропорции, советы по выбору соотношений между размерами шрифтов для различных типов экранов и некоторые основные положения вроде «плавного» изменения высоты. Также стоит заглянуть в Google-таблицу с результатами исследования, потому что они ценны сами по себе и содержат работы экспертов в области типографики, у которых есть чему научиться.
Основные выводы
Наконец, ниже приводится обзор самых важных открытий, сделанных в ходе исследования. Пожалуйста, не принимайте на веру эту статистику. Не обязательно следовать тенденциям, описанным здесь. Важно представлять, как в принципе выглядят шаблоны чужих писем, чтобы потом создать свой стиль и сделать его более читабельным.
- 74% используют шрифты без засечек в основных заголовках, 64% используют шрифты без засечек в теле письма;
- Средний размер шрифта в теле письма при просмотре на ПК – 15,7 пикселя, при просмотре с мобильного устройства – 15,58 пикселя;
- Средняя ширина письма для ПК составляет 623 пикселя;
- Среднее число символов в строке письма, открытого на ПК, – 78,5, при ширине письма в 450 пикселей – 53,86;
- Длина строки в письме, открытом на мобильном устройстве, варьируется от 22 до 57 символов;
- Отношение высоты строки к размеру шрифта на ПК в среднем составляло 1,51 и снижалось до 1,45 на мобильном устройстве (320 пикселей);
- Отношение длины строки к ее высоте в среднем составляло 23,1;
- 76% текста на мобильных устройствах выровнено по левому краю;
- Размеры шрифтов в заголовках десктопных версий делились на две группы: от 24 до 26 пикселей и от 28 до 36 пикселей;
- Размер шрифта в основном заголовке на мобильном устройстве (320 пикселей) в среднем составлял 28,48 пикселя;
- Размер шрифта текста под заголовком на ПК в среднем составлял 12,3 пикселя, на мобильном устройстве – 12,9 пикселя;
- Размер шрифта в заголовках был вдвое больше размера шрифта в теле письма (31,6 и 15,7 пикселя соответственно);
- Отношение размера шрифта текста под заголовком к размеру шрифта основного текста составляло 0,78 на ПК, на мобильных устройствах – 0,85;
- Среднее время, за которое загружается первый элемент письма, составило 0,94 секунды;
- Общее число HTTP-запросов в среднем составило 24.
{kind=link}
Комментарии (0)