В этом выступлении речь пойдёт о штрих-кодах – одномерных и двухмерных баркодах, или матричных кодах. Кодировании, декодировании, некоторых уловках, вспомогательных вещах, неразрешенных проблемах. В отличие от одномерного линейного штрих-кода, где информация закодирована в последовательности и толщине вертикальных полосок, двухмерный баркод, или 2D-код содержит информацию и по вертикали, и по горизонтали.
Мой доклад состоит из следующих пунктов:
- быстрое введение в суть баркодов;
- кодировка и чтение баркодов;
- сканеры;
- простые трюки с баркодами;
- скрытые атаки;
- чтение выбранных образцов;
- нерешённые проблемы и вызовы;
- принципы безопасного использования баркода.
Баркод был придуман в 1948 году Сильвером и Вудландом из Технологического института Дрексель. Первая попытка использования баркода была предпринята в 1950 году – Ассоциация Американских Железных дорог решила использовать его для идентификации вагонов и потребовалось свыше 17 лет для того, чтоб пометить 95% составов и после система так и не заработала. В это время люди считали баркоды бесполезными.

Но уже в 1966 году Национальная Ассоциация продуктов питания предложила наносить баркоды на продукты, чтобы ускорить процесс их идентификации на кассе и заработать побольше денег. В 1969 году эта же Ассоциация создала промышленный стандарт Универсального Продуктового Идентификационного кода (позже UPC), который стал использоваться с 1970 года.
В 1981 году Министерство обороны США потребовало, чтобы все продукты, поставляемые для армии, маркировались Code 39 – штрихкодом, позволяющим кодировать большие латинские буквы, цифры и символы и Вы далее увидите, почему это было плохой идеей.
Штрих-коды делятся на одномерные и двумерные. Вот так выглядят одномерные штрих-коды разного стандарта:

Некоторые из них содержат только цифры, некоторые и цифры, и буквы. Существует несколько стандартов изображения информации на штрих-коде.

Они различаются интервалом между полосками, разрешением для печати и так далее. На следующей картинке Вы видите особый штрих-код, который часто встречается на почтовых конвертах. Это код Postnet, вместо него в Великобритании используют похожий код BPO 4. В них содержится маршрутная информация для писем.

Вот так выглядят двухмерные коды – скажите мне, какой из этих кодов напечатан на Ваших бейджах? Правильно, он называется Data Matrix. Он отличается от других своеобразным крестом, который делит этикетку на 4 равных части. В них закодированы 4 блока разной информации.

MAXICOD и Aztec code редко используются в США, я однажды видел MAXICOD на посылке от Cisco. PDF417 широко распространён в Европе, например, для билетных систем.
Для того, чтобы расшифровать баркод, используют 2 способа. Можно взять сканер, поднести его к этикетке, сканер издаст сигнал, после чего прочитанная информация появится на экране Вашего компьютера. Ручные сканеры недорогие и настраиваются для чтения штрих-кодов разного вида.
Второй способ заключается в использовании программного обеспечения для расшифровки. Это то, чем я пользуюсь. Одни программы бесплатны, другие стоят несколько сотен долларов, хотя их легко взломать. Я ленивый человек, поэтому как настоящий капиталист, использую платную программу Omniplanar SwiftDecoder, она довольно дорогая, зато очень хороша.
Большинство сканеров подсоединяются к компьютеру через USB и содержат модуль расшифровки внутри себя. Поэтому Вам не нужно использовать специальное ПО для сканера.

Также существует разное программное обеспечение для создания штрих-кодов. С помощью бесплатных GNU программ можно создавать только одномерные штрих-коды, причём в неограниченном количестве. Можно использовать различные онлайн генераторы баркода, которые создают его с помощью PHP-скриптов, а число коммерческих программ бесконечно. Писать генераторы штрих-кодов не трудно, обычно нужно заплатить только за скрипты, или спецификации, большинство из которых стоят меньше $20. Например, я покупал спецификации для Aztec code, чтобы написать свою собственную программу.

Баркоды в основном используют для трёх целей, и пусть меня немцы простят, но я не могу подать это в другом свете, применив другие слова для описания:
- для идентификации, в качестве этикетки;
- для быстрой передачи данных с визуального носителя (визитной карточки) в физическое устройство, например, в смартфон;
- для всяческого хулиганства, например для обмена зашифрованными ругательствами, я называю это GGU, Ganz Grober Unfug, что в переводе с немецкого означает «очень грубая выходка».

Практически любой сканер можно настроить на чтение разных баркодов – нужно подсоединить его к компьютеру, затем прочитать код доступа Enter Configuration, отсканировать образец нужного кода и затем просканировать код сохранения Save Configaration.
Как Вам поступить, чтобы сконфигурировать сканер? Нужно зайти на страницу продавца Вашей модели сканера, или на сайт производителя, или на сайт технической поддержки или, в конце концов, позвонить им и получить таблицу конфигурации. Для того, чтобы перенастроить сканер на чтение другого кода, нужно поменять тип совместимого баркода, поменять CRLF или характер дешифровки. Большинство сканеров поддерживают клавиатурные коды, такие как «Выйти» ESC, «страница вверх» PageUp, «страница вниз» PageDown, «удаление» DEL и так далее, благодаря этому Вы можете использовать команду ESC на сканере так же, как будто нажали эту клавишу на клавиатуре компьютера. Некоторые сканеры позволяют обновить собственную прошивку с помощью чтения соответствующего штрих-кода. Потому может быть довольно просто взломать систему целого торгового центра.

Вы должны знать, что любой сканер поддерживает абсолютно любой баркод, и Вам не нужно покупать отдельные сканеры для чтения разных типов штрих-кодов.
Самым простым способом взломать штрих-код является его копирование. Вам не нужно расшифровывать код, если Вы знаете, что он Вам даёт. Для копирования понадобится хорошая цифровая камера и принтер.

Вы фотографируете штрих-код на чужом бейдже, визитке или приглашении, распечатываете его на принтере и получаете копию. Использовать такую копию можно там, где это Вам нужно. Например, баркод на бэйдже одного из гостей отеля позволяет пользоваться бесплатной выпивкой. Вы фотографируете его, печатаете себе бейдж с таким же штрих-кодом и бесплатно пьёте пиво, будто бы «загрузили» деньги на свой бейдж, вот почему на нашей конференции чипованные карты :) Скопированный штрих-код поможет Вам проникнуть в нужное место, если у Вас нет доступа, а у кого-то он есть. Достаточно сфотографировать этот баркод и присвоить себе.

В прошлом году в Европе, в Германии, я некоторое время жил в одном отеле в Дрездене. Так вот, на подземном паркинге отеля автомат не видит разницы между въездным и выездным талончиком. На них одинаковые штрих-коды. Вы можете бесплатно пользоваться паркингом, если скопируете такой талончик. Кроме того, у них есть бессрочные парковочные талоны, они дают Вам такой, когда Вы останавливаетесь в отеле. Мне не нужно распознавать код на таком талоне – я просто копирую его, печатаю кучу таких талончиков и раздаю их как право на бесплатную парковку в центре города, что я и сделал, и Вы можете пользоваться бесплатной парковкой вечно.

А ещё там есть автоматы, принимающие пустую тару, например, пластиковые бутылки, для последующей переработки. Сделать такой автомат было плохой идеей. Вам требуется как правило больше времени, чтоб положить бутылки по одной в приёмочный отсек, нежели уйдёт на то, чтоб выпить бутылку пива. Вы кладёте в него бутылку, она исчезает внутри и это всё происходит чрезвычайно медленно, а взамен автомат выдаёт вам ваучер со штрих-кодом. Этот ваучер можно обменять на деньги или использовать при покупке продуктов в супермаркете. Так вот, достаточно скопировать один ваучер и напечатать сотню, предъявить их на кассе и получить деньги.

Это стало возможным благодаря тому, что автоматы не соединены друг с другом и с кассовыми аппаратами, нет обмена информацией, поэтому люди просто копируют ваучеры. Однако правильный ваучер печатается на бумаге с водяными знаками, и копию могут заметить.
Рассмотрим, как с помощью скопированного штрих-кода можно заплатить за пиво. Попробуем расшифровать штрих-код EAN13, который начинается с кода страны происхождения продукта, а число 2 означает, что этикетка используется только для применения внутри магазина.

Следующие 6 цифр являются командой кассовому аппарату на возврат денег, ещё 5 цифр указывают на объём или количество продуктов. Последняя цифра – это проверочный код EAN13 (контрольная сумма), он равен значению 10 минус сумма всех предыдущих цифр. В целом это позволяет вернуть до 999 евро, что весьма порядочно.

Зная это, Вы можете сгенерировать свой собственный баркод и наклеить его на нужный товар. Замечу, что в Берлине живёт множество людей, которые не очень любят работать, зато любят выпивать. Если Вы подадите им эту идею, они будут Вам очень благодарны и побегут в магазин, чтобы получить дармовые деньги.
Чтобы предотвратить такие махинации, магазины применяют свою собственную бумагу, которую легко распознать. Но если Вы наклеите фальшивую этикетку со штрих-кодом на дно тяжёлой упаковки из 6 банок или бутылок и не будете слишком жадными (сумма не привлечёт внимание), девушка на кассе не захочет её переворачивать, чтобы рассмотреть бумагу, на которой она напечатана. Кассирша просто приподнимет её и проведёт сканером снизу, чтобы считать информацию.
Следующая область применения баркода – это контроль доступа. Множество компаний используют штрих-код для контроля физического доступа. Однако не все знают, что обычно система контроля просто проверяет, правильно ли сформирована структура данных. Проще говоря, она проверяет, баркод ли это или просто набор случайных графических элементов. Простой тест: бывает достаточно показать сканеру системы вместо штрих-кода на пропуске штрих-код на пачке сигарет, и дверь откроется.

Рассмотрим вещь, которая называется десинхронизацией. На пропуске люди читают номер, расположенный выше штрих-кода, а сканеры и системы идентификации читают то, что зашифровано в самом баркоде, и эти данные не должны совпадать. Поэтому Вы должны заменить либо эти цифры, либо сам баркод.

Рассмотрим эту операцию на примере билета в Берлинский зоопарк. Под штрих-кодом напечатаны одни цифры, например, 3711679, а расшифровка самого кода даёт такие цифры – 49864088922304. Поэтому если Вы копируете такой билет, помните, что эти последовательности цифр должны отличаться друг от друга.

Как использовать десинхронизацию для завладения чужим имуществом? Допустим, Вы работаете в компании, и рядом с Вами сидит парень, у которого ноутбук намного круче, чем у Вас, и Вы хотите забрать его ноутбук себе. Дело в том, что для использования казённой техники сотрудник, работающий по контракту, получает штрих-код. Этот код наклеен на ноутбуке, и такой же код имеется на пропуске или бейдже. Если коды совпадают, можете брать и пользоваться данной техникой. Право пользования техникой проверяется, когда работник входит в здание офиса.

Для этого Вы копируете баркод с бейджа законного владельца, именно баркод, а не номер, и помещаете его на свой бейдж. Дожидаетесь, пока парень закончит работу, выносите его компьютер из здания, затем возвращаетесь обратно, меняете код на бейдже на свой собственный и спокойно идёте домой.
Точно таким же образом Вы можете получить доступ к сети или к данным, которых у Вас нет. Допустим, для входа в сеть используется MAC-адрес компьютера, который принадлежит другому сотруднику, или его инвентарный номер. MAC-адрес обычно нанесён на само устройство, здесь же находится серийный номер и наклейка собственника со штрих-кодом. Скопировав баркод с бейджа законного владельца, Вы можете завладеть информацией коллеги или нанести на этот баркод броадкаст МАС, который содержит только F, и положить сеть.

Какие ещё трюки можно проделывать со штрих-кодами? В Германии Вы сможете бесплатно пользоваться круглосуточной автоматической системой проката DVD-дисков Video24, которая находится, в том числе и в моём доме, без присмотра, и мне интересно было разобраться с ней. Что нужно обычному пользователю, чтобы за деньги посмотреть фильм на DVD-диске? Членскую карточку с баркодом, ПИН-код или даже биометрическую аутентификацию по отпечатку пальца. Процедура проката такова: Вы сканируете карту, вводите ПИН, выбираете фильм, выходите из сеанса, а затем смотрите фильм на компьютере или телевизоре. Так можно заказать фильм через веб-сайт.

Если Вы хотите взять фильм на физическом носителе, DVD-диске на прокат из автомата, достаточно просто отсканировать карту и забрать его. Чтобы вернуть диск, нужно снова «прокатать» карту, ввести ПИН-код и положить диск обратно в автомат. В чём тут проблема? Вам не нужно вводить пин-код.

Итак, на карте имеется баркод, обозначенный буквой и четырьмя цифрами. Буква совпадает с первой буквой фамилии клиента. Вам достаточно отсканировать этот баркод у своего знакомого, поменяв только цифры, и когда он закажет фильм по интернету, получите его Вы! Естественно, друг этот фильм не увидит, но доказать это будет невозможно, поэтому он будет вынужден оплатить просмотр. Так Вы сможете просмотреть DVD и даже получить его в автомате. На сайте ведётся учёт предзаказов, поэтому Вы можете выбрать тот диск, который никто ещё не заказал, и гарантированно его просмотреть.
Следующий трюк называется «Иньъекцирование и мультирасшифровка». Большинство сканеров штрих-кода выпускаются с заводскими настройками. Даже если настройки изменены, Вы всегда сможете их реконфигурировать. Встроенные приложения для расшифровки в большинстве случаев использует тот тип баркода, для которого были написаны, обычно EAN13 или 2о5.

Используя более мощную кодировку Code 128, можно ввести в считываемый штрих-код случайные данные, такие как скрипты на языке SQL, раздельное шифрование или форматирование строк. Чем новее системное приложение, тем лучше работает такая технология. Возьмём для примера медицинские исследования. Вы можете изменить программную «начинку» сканера так, что реальный штрих-код, нанесённый на пробирки с анализами, будет читаться как совсем другие данные. То есть Вы сможете подменить результаты анализов, и никто этого не заметит.
Следующий трюк – чтение QR-кодов. Эти коды работают как гиперссылки. Предположим, у Вас есть газета. Настоящая газета, такая, которую мы, хакеры, не видим годами! Вы можете сфотографировать двухмерный баркод с её страницы. Коммерческие программные декодеры конвертируют его в HTTP ссылку, а затем программа заставляет браузер Вашего мобильного устройства открыть страницу, расположенную по этому адресу.

В действительности это очень плохая идея, и я объясню, почему.

Дело в том, что обычно этот баркод не ведёт напрямую на сайт газеты Die Welt, где расположена статья, а сначала посылает Ваш браузер на коммерческий сайт, как это показано на картинке.
При дешифровке этого штрих-кода выясняется, что возможно впечатывать в баркод газет случайный контент, и это называется рекламой. Однако большинство деловых людей доверяют своим газетам, по крайней мере, они считают их безопасными.
Но браузер мобильного устройства, пройдя по такой ссылке, может подхватить вирусы или сторонние куки. Он автоматически, без Вашей воли, подхватывает рекламу или кое-что похуже. То есть чтение такого штрих-кода делает Ваш браузер уязвимым. В результате Вы получаете:
- угрозу XSS, или межсайтовый скриптинг, то есть при открытии указанной страницы на Вашем устройстве может быть выполнен вредоносный скрипт;
- ссылка может перехватить контроль над Вашим почтовым ящиком;
- ссылка может направить Вас на сайт с вирусами;
- переход по ссылке может загрузить в Ваш телефон бинарные коды с вредоносного сайта.
Вам это нужно? Конечно же, нет! Поэтому никогда не считывайте баркод со страниц газет, это опасно!
Баркоды обладают ещё одной великой способностью. Это плотность расположения полосок одномерного баркода. От неё зависит длина штрих-кода и его читаемость. Вы можете напечатать баркод любой длины, закодировав в нём массу информации. Однако сканеры и идентификаторы работают с баркодами определённой длины, они рассчитаны на чтение ограниченного количества цифр. Таким образом, выбирая плотность полосок, Вы можете напечатать в пределах одного физического пространства намного больше информации. Для этого необходимо использовать лазерный принтер с высоким разрешением печати, иначе полоски кода сольются, и он станет нечитаемым. Кстати, заметили ли Вы, что получение сканером большего количества информации, чем ожидалось, является целью тех людей, которых принято называть хакерами?
Итак, чтобы чтение баркода вызывало переполнение буфера сканера и вызвать проблемы, выбирайте большую плотность печати. Вашим любимым кодом для создания штрих-кодов должен стать Code 128, потому что он имеет полноценный 7-ми битный набор кодов ASCII и использует контрольный функциональный код FC4.

Вернёмся к баркодам, которые печатают в газете и которые направляют Ваш браузер по ссылке. Воспользовавшись дизассемблером, мы увидим, что QR-код может также содержать номер используемого приложения, телефон компании, логин и пароль пользователя и адрес стороннего сайта, на который осуществляется вход.
Рассмотрим ещё одну вещь, которая есть в Германии и которую не удалось сломать. Это станции упаковки, или Pack Station. Вы приходите сюда со своим почтовым конвертом или посылкой, и эта станция печатает Вам наклейку со штрих-кодом, которую Вы наклеиваете на своё почтовое отправление. А потом сюда приходит сотрудник UPS, который не всегда может найти дверь, чтоб забрать Вашу почту.

Так вот, я скопировал множество баркодов в свою записную книжку и попытался взломать ими сканер упаковочной станции, обмануть его, но так и не смог ничего с ним сделать. Вероятно, это потому, что этот сканер читает любые одномерные баркоды, используют только цифровую кодировку 2о5 и его программное обеспечение вообще «никакое».
Ещё одно полезное замечание: если мы сможем разгадать предназначение баркода, то мы сможем создать свой собственный код. Это достаточно просто.
Следующая наша цель – почтовые коды. Почтовые службы всё чаще используют двухмерный матричный баркод вместо обычных марок. Им не нужно больше клеить марки, они просто печатают баркоды на конвертах и экономят себе время. Преимущество такого решения состоит в автоматическом создании такого кода и его автоматическом распознавании. Некоторые почты используют свои собственные типы штрих-кодов, с которыми работают не все сканеры.

Что именно проверяют почтовые сканеры, какие данные они верифицируют? Это зависит от предназначения штрих-кода. Рассмотрим конверт письма, которое я получил от одной австралийской компании. Здесь есть код ASCII, состоящий из одних нулей. Стоимость письма нулевая, потому что компания не платила за его отправку, она отправляет письма бесплатно. Если я напечатаю на конверте такой же код и отправлю письмо в Австралию, то мне тоже не придётся за него платить.

Ещё два цифровых кода в кодировке 2о5 обозначают почтовую информацию и к стоимости отправления никакого отношения не имеют.
Почтовые коды в США другие. Система нанесения штрих-кодов называется «Интеллектуальная почта». Здесь используется кодировка Code 128, и её скрипты, или спецификации, можно легко найти в Интернете в виде файла в формате .doc. То есть вся информация штрих-кода легко расшифровывается.

Однако эта информация не содержит никаких указаний, что Вы являетесь получателем данного письма, то есть что оно адресовано именно Вам. Она только указывает, что отправителю письма присвоен уникальный код. И его можно найти по этому коду в течении 30-45 дней, потому что после этого срока информация о человеке, отправившем Вам письмо, удаляется из базы данных почтовой службы. Эта уникальность никак не защищена, потому что находится в общем штрих-коде. То есть цифры с 10 по 18 можно подменить, чтобы отправителя невозможно было отследить. Посмотрим на рекомендации Пентагона, в которых описано, как распознать опасные почтовые отправления, или как уберечься от бомбы в письме. Здесь написано, что к опасным письмам относятся:
- отправления из-за границы;
- особые пометки типа «конфиденциально», «персонально для…»;
- адрес, написанный от руки или плохо пропечатанный;
- нет адреса отправителя;
- вес письма больше, чем указано;
- видны проводки или металлическая фольга, и т.д.
При этом доверие к идентификационному номеру отправителя не подлежит сомнению. Если штрих-код письма содержит ID-отправителя, значит, с ним всё в порядке. Получается, что Вы можете отправить что угодно, кому угодно и куда угодно, причём совершенно бесплатно, если укажите в штрих-коде ID, что отправителем является Пентагон, Министерство обороны США, потому, что ему доверяют.
Рассмотрим теперь билеты на самолёт. Сейчас модным трендом является заказ билетов по Интернету и распечатка на домашнем принтере. Служба безопасности аэропорта Франкфурта-на-Майне требует, чтобы на всех билетах, заказанных через Интернет или купленных в кассе, обязательно был штрих-код. Я часто летаю, поэтому хочу показать Вам свои билеты с баркодами.

Вот так выглядит моя программа для расшифровки баркодов на билетах. Она сделана в разных цветах для лучшего восприятия. Здесь я нашёл всю информацию: имя пассажира, номер, код брони, дату вылета, куда летит, номер рейса, класс, место, номер билета. Последняя цифра – код безопасности, который служит для идентификации пассажира. Однако он статичен, то есть не меняется. Таким образом, мы можем напечатать свой собственный билет со своим собственным штрих-кодом, вписав туда всё, что нам надо, в том числе и код безопасности. Это плохо, потому что совершенно не защищает от проникновения на борт самолёта опасных людей.

Красным цветом я обозначил данные кода безопасности, который Вы получаете при заказе билета по Интернету. Во второй колонке занесены данные, которые проверяет сканер при посадке, и кода там нет. То есть он проверяет Ваше имя, место, дату, но не идентифицирует Вас. Нет подтверждения того, что человек, заказавший билет, и человек, прошедший на борт самолёта, одно и то же лицо.

Рассмотрим багажные талончики. Они также снабжены одномерным штрих-кодом и прикрепляются к Вашему посадочному талону, с которым Вы проходите в самолёт. Баркод на талончике обеспечивает маршрутизацию, так как на нём указано, куда отправлять багаж. То есть не существует никаких доказательств, что багаж принадлежит именно Вам, кроме этого талончика, прицепленного к билету. Вы показываете его при получении и забираете свой багаж.
Рассмотрим такой сценарий. Есть человек, Абдул Бен Шузал, потенциальный террорист, только потому, что он носит одеяла. У него имеется посадочный талон. И есть второй человек, агент, Эрнст Аджент, который хочет сделать, чтоб Абдул выглядел, как настоящий террорист. Он копирует его багажный талончик, прикрепляет его к чемодану с бомбой, сдаёт чемодан в багаж, тот просвечивают рентгеном и находят бомбу. Далее понятно — Абдулу задерживают, как террориста, потому что багажный талончик принадлежит ему. Таким образом, можно сделать нелегальным любой багаж. Даже бутылку с водой. Если Вы покупаете её за пределами аэропорта за $1, Вам не разрешат пронести её на борт. Но если Вы покупаете точно такую же бутылку в аэропорте за $5 – всё в порядке, можно взять её с собой.
А сейчас я расскажу вам про штрих-коды, которые нельзя подделать. Я выяснил, что таких всего три, и взломать их – неразрешимая задача.

Это баркод Почты Германии, баркод платных немецких автодорог и баркод иммиграционной визы США. Они полностью зашифрованы и не содержат отдельных элементов, подверженных дешифровке.
Вот принципы, которые обеспечивают безопасную генерацию штрих-кодов с помощью программного обеспечения:
- считайте, что баркоды похожи на куки браузера: их можно перехватить, скопировать, модифицировать, потерять и т.д.
- если Вы создаёте только одномерные штрих-коды, Вы должны быть уверены, что они содержат только случайные ID-коды, и не пытайтесь «впихнуть» туда как можно больше информации;
- если Вы делаете двухмерные коды, пользуйтесь настоящим шифрованием – это не дорого и гарантирует, что такой код не будет отвергнут сканером при дешифровке;
- убедитесь в работоспособности своего творения: если сканер признает Ваш баркод настоящим, Вы победили! Убедитесь, что есть связь между наклейкой и помеченной ею вещью. Не существует браузера, который мог бы это проверить.
- никогда не доверяйте напечатанным цифрам!
Надеюсь, доклад был в некоторым роде интересным.
Если Вы хотите «поиграть» с написанием штрих-кодов, или расшифровкой уже имеющихся и всем, что связано с этим, Вы можете посетить lagune.cyphertext.de/twiki.
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас:Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
Let's block ads! (Why?)











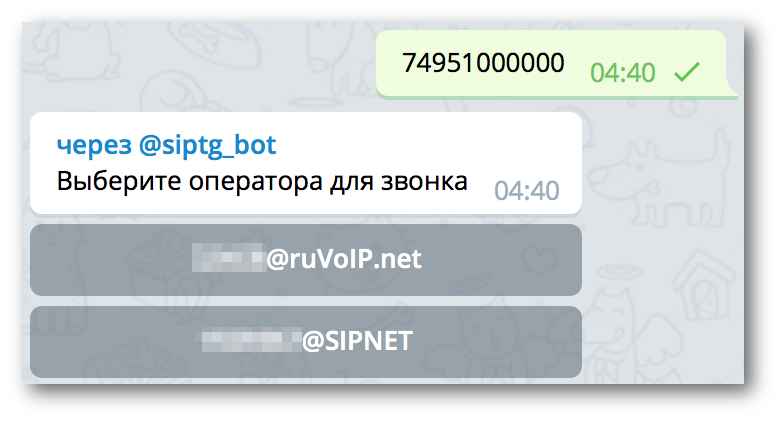
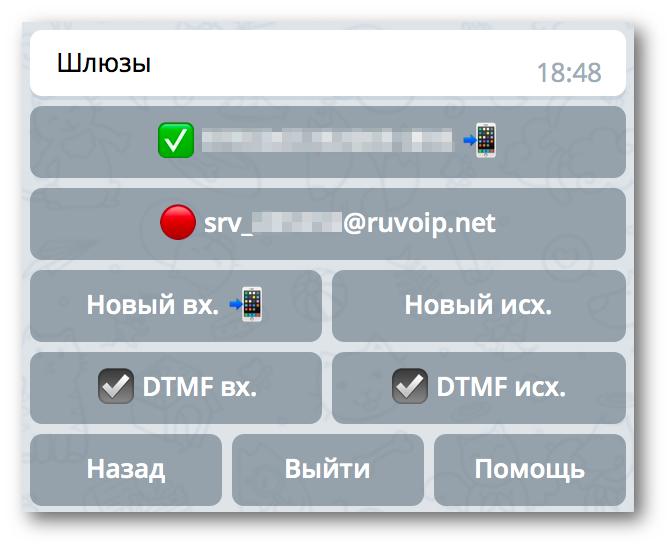
 Уверен, многие задавались вопросом: вот есть Телеграм, год назад он обзавёлся звонками, у него открытое API, но почему-то до сих пор никто не сделал связку с протоколом SIP. Ведь это даёт неограниченные возможности: от замены SIP-звонилок до организации ещё одного канала коммуникации с пользователями Вашего бизнеса. Сегодня я расскажу историю появления первого такого шлюза, который теперь доступен абсолютно всем!
Уверен, многие задавались вопросом: вот есть Телеграм, год назад он обзавёлся звонками, у него открытое API, но почему-то до сих пор никто не сделал связку с протоколом SIP. Ведь это даёт неограниченные возможности: от замены SIP-звонилок до организации ещё одного канала коммуникации с пользователями Вашего бизнеса. Сегодня я расскажу историю появления первого такого шлюза, который теперь доступен абсолютно всем!




.jpg){kind=link}
{kind=link}